
2025-04-28

Innovation Highlights
1. 蒋力提出了一种创新的端到端稀疏编译优化方案—CROSS,为 AI 推理带来细粒度稀疏计算的加速效果。在现代 AI 模型的快速迭代中,如何在保持模型精度的同时提升计算效率成为关键课题。尤其在大规模 AI 推理中,非结构化稀疏矩阵的计算效率低下成为难以突破的瓶颈。面对这一挑战,蒋力团队针对稀疏矩阵中非零元素的分布非均匀特性,提出了稀疏计算核与密集计算核协同的编译优化方案,通过批内核批间负载均衡策略缓解了稀疏分布不均匀带来的计算单元负载失衡的问题。
Achievements Summary
编译驱动的稀疏-密集计算核优化—CROSS
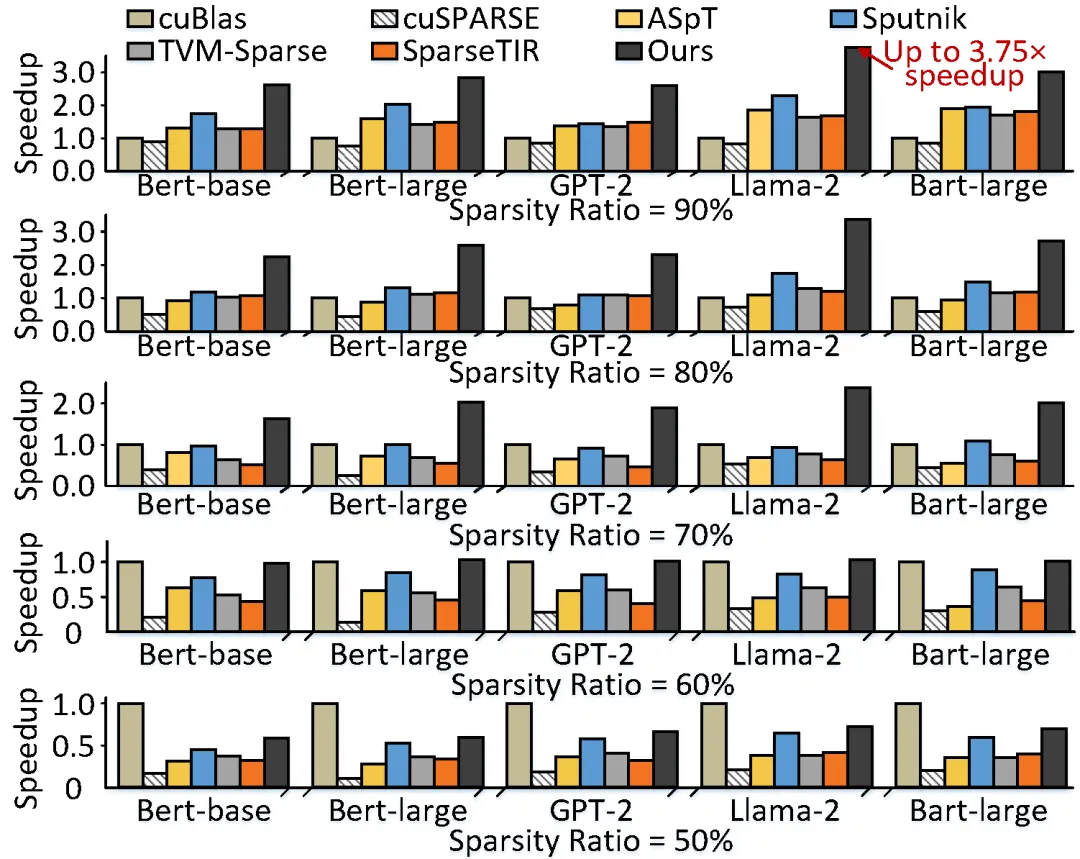
图1. 五种不同稀疏率下的推理性能比较(NVIDIA A100 GPU)
非结构化细粒度稀疏场景下模型推理效率低下问题是 AI 编译社区面对的关键问题之一。相比于密集算子加速库(cuBlas),主要的稀疏算子加速库或编译框架需要在较高稀疏率下才能获得收益,而过高的稀疏率需求可能使团队面临模型精度下降的风险。
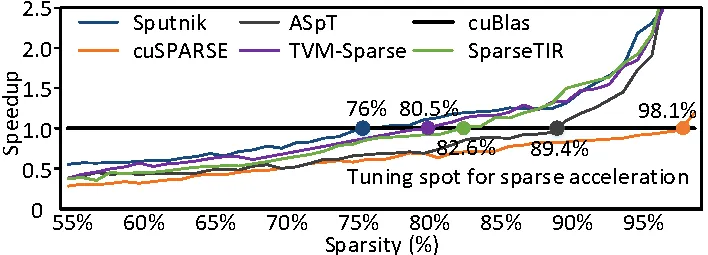
图2. 相比于cuBlas,不同稀疏加速库或编译框架在不同稀疏率下的加速比
通过对稀疏模型进行调研,团队发现,稀疏矩阵中非零元素的分布展现出严重的非均匀分布特性。这种非均匀分布对稀疏矩阵的计算效率产生了巨大的负面影响:局部过密:部分区域的非零元素过于密集导致该区域不再适合稀疏矩阵运算;局部过稀:部分区域的非零元素过于稀疏导致该区域相对于其他区域负载过低,造成计算单元负载失衡问题。这些问题严重影响了稀疏算子的执行效率。
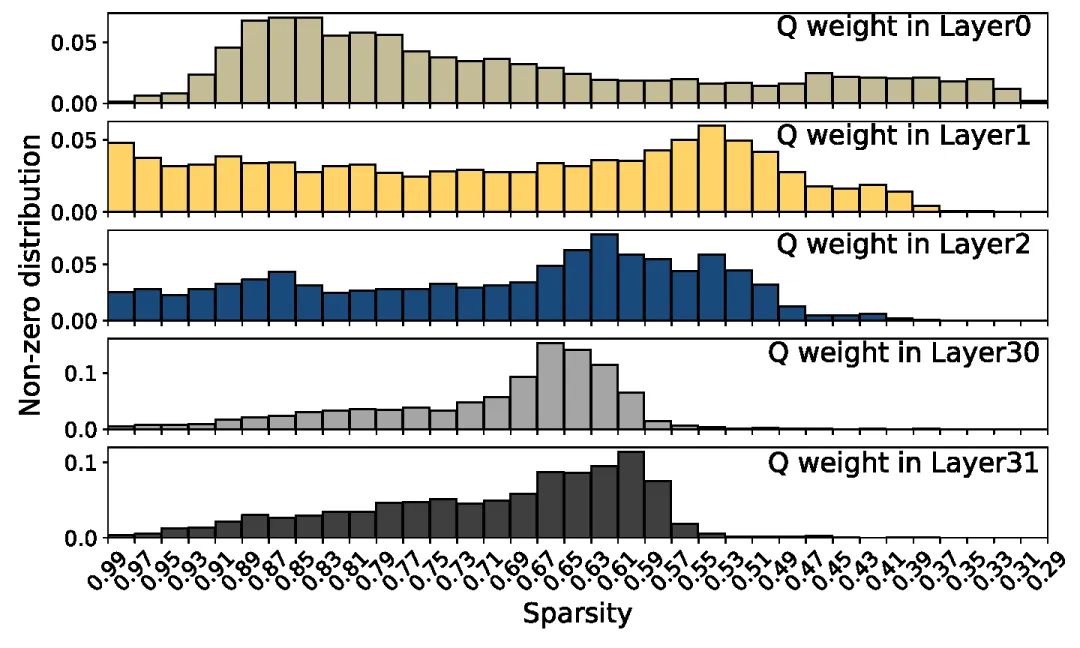
图3. Llama-2-7B 模型整体 70% 稀疏率场景下非零元素的分布
为应对上述挑战,CROSS 引入了一套全新的编译优化流程。CROSS 首先对稀疏矩阵的结构特点进行深入分析,通过代价模型精准判断稀疏与密集区域的不同计算需求,并自动分配最优的计算资源。其关键步骤包括:
(1)代价模型构建:首先,团队对不同 block 形状下、不同稀疏率下的稀疏矩阵乘(SpMM)和密集矩阵乘(GEMM)执行时间进行分析并建立代价模型(block 内的稀疏分布假设为均匀分布)。SpMM 开销明显高于 GEMM 开销的稀疏率范围称为密集区(Dense band);将 SpMM 开销明显低于 GEMM 开销的稀疏率范围称为稀疏区(Sparse band),将 SpMM 与 GEMM 的执行开销相近的区域称为摇摆区(Swing band)。
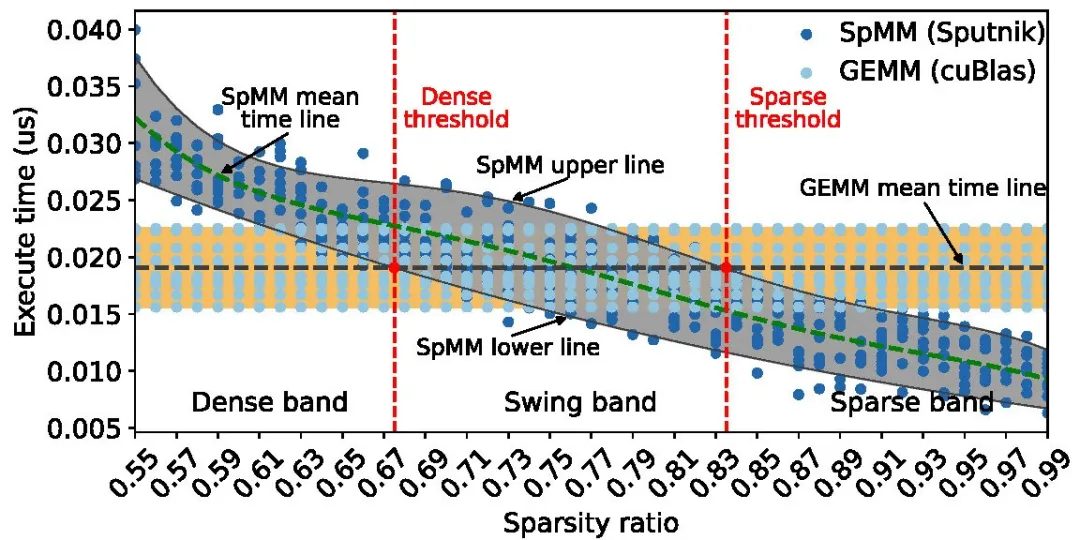
图4. 不同稀疏率下SpMM与GEMM的执行时间分布
(2) Intra-batch 负载均衡:其次,团队将模型中的稀疏矩阵拆分为多个 block 并依据代价模型评估每个 block 适合的计算范式和计算开销。然后,团队依据 block 之间是否具有累加关系对整个矩阵的计算开销建立代价模型。针对矩阵中存在的负载不均衡问题,团队将稀疏计算与密集计算分别映射到不同的计算单元执行。当稀疏计算与密集计算的负载差异较大时,团队将摇摆类型的 block 转换为负载较小的类型,以实现单 batch 稀疏矩阵乘法的计算单元负载均衡。
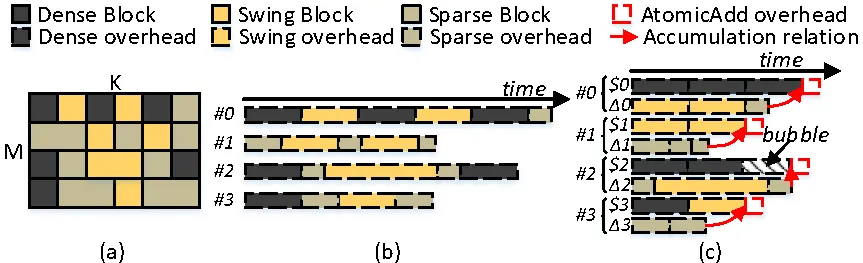
图5. Intra-batch负载均衡策略
(3)Inter-batch 负载均衡:此外,由于 batch 之间使用相同的稀疏权值矩阵,当 batch size 较大时,矩阵中不同位置的负载失衡问题持续积累而变得更加严重。针对该问题团队将相邻两个 batch 之间的负载与计算单元的映射关系进行了重排。简单将相邻两个 batch 合并执行会造成不同位置的负载失衡效应持续积累,造成更严重的负载失衡问题。为了应对该问题,团队对不同计算单元的负载进行重排序,相邻两个 batch 按照不同的顺序进行计算单元映射,以实现 batch 之间的负载均衡。
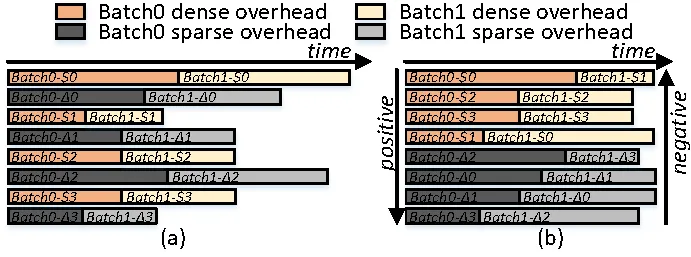
图6. Inter-batch负载均衡策略
实验结果表明,相比于其他稀疏矩阵加速库或编译框架,CROSS在不同稀疏率下都获得了显著性能提升,与业界最优设计相比平均获得2.03×的性能提升。相比于密集计算(cuBlas),CROSS 在稀疏率超过60%时开始获得正收益,显著突破了传统无规则稀疏加速设计的收益边界。
本工作一作为上海期智研究院兼职研究员、上海交通大学助理教授刘方鑫,上海期智研究院实习生、上海交通大学博士生黄世远,通讯作者为上海期智研究院PI、上海交通大学教授蒋力。
论文信息:
CROSS: Compiler-Driven Optimization of Sparse DNNs Using Sparse/Dense Computation Kernels, Fangxin Liu, Shiyuan Huang, Ning Yang, Zongwu Wang, Haomin Li, Li Jiang†, https://meowuu7.github.io/QuasiSim/, HPCA 2025







