
2025-04-27

Innovation Highlights
1. 冷静文—提出向量量化(Vector Quantization)大模型的高性能算子生成系统,成功地将向量量化的大模型推理性能提高到工程可用的水平,在提供与传统量化方式相似的加速比的同时,显著提高量化质量。团队细致分析目前向量量化推理的瓶颈,发现其编码本在存储和计算层面为高性能算子生成带来了较大的挑战。为此团队提出了一套向量量化编码本感知的代码生成框架,由编码本缓存和编码本中心计算引擎组成。在多种大模型的算子上,系统显著降低50%的延迟,相比现有开源实现有百倍提升。
2. 冷静文—提出了一种面向大模型的新型数学自适应数值类型(M-ANT),显著提升细粒度组量化在推理过程中的性能与灵活性。团队深入分析大模型中不同组间分布差异较大的现象,发现现有的自适应数据类型难以满足小粒度组内的分布变化。为此,团队设计了M-ANT编码范式及解码-计算融合机制,并开发出组级数据类型自动分配框架以及实时量化机制。通过构建专用PE硬件单元与脉动阵列集成,该系统统一支持权重量化与KV cache量化。在多种大模型任务上,系统平均加速达到2.99倍,最高可达4.46倍,同时能耗降低最高达4.10倍,优于现有最先进的加速器方案。
Achievements Summary
向量量化大模型的高性能推理算子代码生成 VQ-LLM
随着大语言模型的快速发展,算法研究者逐渐开始探索向量量化(Vector Quantization,VQ)的应用。VQ方法虽能大幅压缩模型权重和KV缓存(内存占用降低至1/8),但由于编码本访问效率低与计算数据流不协调,实际推理延迟反而可能高于FP16基线。VQ-LLM通过编码本缓存和编码本中心计算引擎两大核心技术,实现了超过50%的延迟降低,性能媲美甚至超越同比特宽度的传统逐元素量化方法,为VQ技术的实际部署提供了可行性方案。
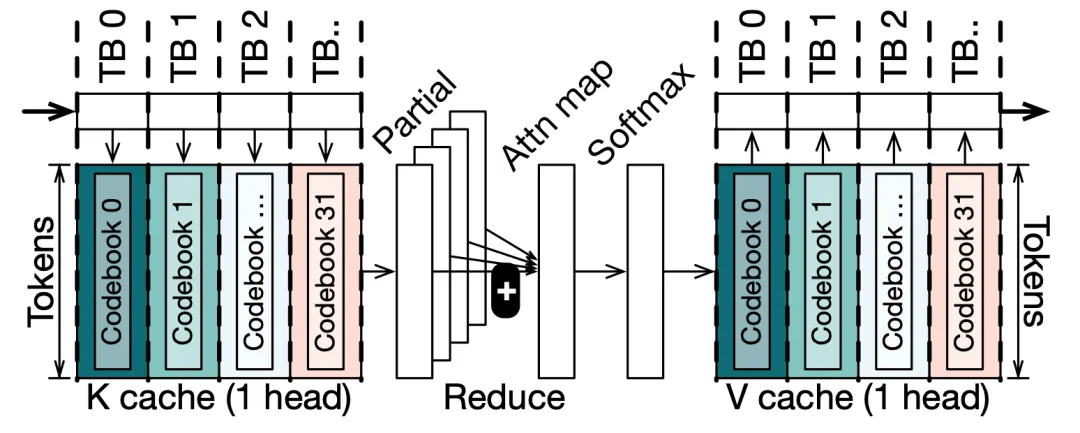
图1. 基于CQ配置的注意力机制(解码)
计算中以码本为核心的数据流示例
VQ将向量作为压缩单元,相比逐元素量化(如INT4),能更高效捕获跨维度信息,在相同比特下实现更高精度,或在更低比特(如2-bit)保持等效精度。如图所示,目前的算法工作中,VQ在Weight-Only和KV Cache压缩中均有优于传统逐元素量化的解决方案:
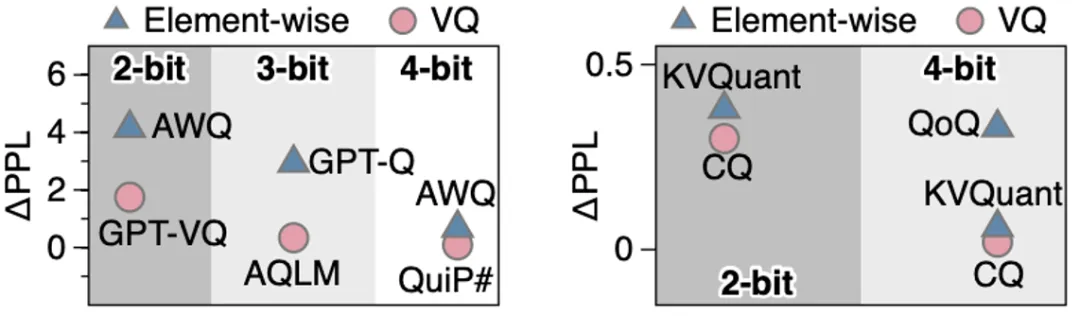
图2. 向量量化(VQ)与逐元素量化的精度对比
然而,现有VQ方法存在编码本访问效率低、计算与量化流程不协调两大问题。此外,由于VQ一次性解码多个连续元素,这些元素的布局(Layout)可能与后续计算需要的布局不匹配,也会导致额外的片上共享内存开销和流量(用于数据的重排)。
本工作通过代码本缓存和计算引擎优化解决上述挑战。
(1)分层代码本缓存
全局内存→共享内存→寄存器三级存储:团队观测到了编码本具有显著的冷-热访问模式,这就意味着团队不需要把所有的编码本条目都放在片上存储中,如下图所示,访问频次高于平均值的仅占一半不到:
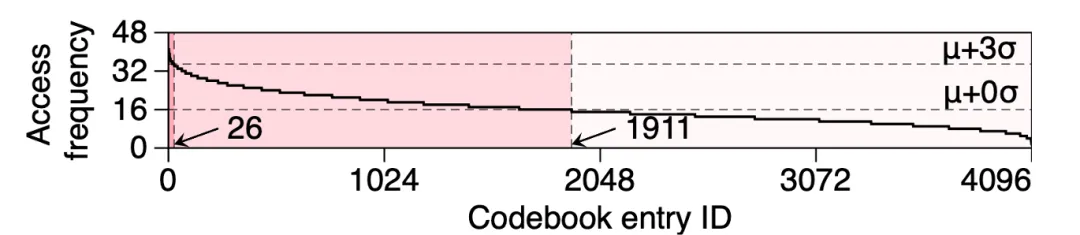
图3. VQ-GeMM内核中单线程块对码表项的访问频率统计
此外,由于VQ中的编码本存在显著的随机访问,无法完全避免Bank Conflict问题,故将访问最为频繁的编码本条目放进线程独有的寄存器(Register)不失为一个好的选择,可以完全避免这些最热条目访问时被Bank Conflict阻塞。
(2)代码本中心计算引擎
数据流优化:按代码本切换轴拆分任务,最小化全局内存流量,通过自适应分块平衡计算与通信开销。直接得,本工作直接以编码本训练、组织方式位为基准划分任务。如Attention计算中,CQ算法以Head Dimension划分训练、组织编码本,团队则对其这一划分方式,指定不同线程块进行不同Head Dimension的计算。这样会导致产生Partial内积结果,对于这部分结果,团队使用L2缓存中的空间执行Reduction操作。需要注意的是,这一过程中原先需要进行的Partial Softmax计算不再需要,故这一方法的核心便是新计算方式中的Reduction数据量和重复编码本加载带来的数据量的权衡。团队使用这两者来确定如何对任务进行划分。
分层融合技术-寄存器级融合:利用GPU线程内数据交换(Intra-Warp Shuffle),直接重组数据布局,避免共享内存往返。现代的GPU提供了线程束(Warp)级别的数据交换API:__shfl_[rule]_sync(),这一API能够直接交换同一个线程束之间的寄存器数据。这为团队直接在寄存器中重排数据到需要的排布带来了可能。文中团队提供了详细的算法以处理更多不同的数据排布需求。通过这一方式,团队有效避免了通过共享内存进行数据排布的开销,还节省了共享内存的使用量。
在LLM常见Kernel中,相比无优化的实现,延迟降低50%。注意此处无优化的实现已经显著优于AQLM、QuiP#等算法工作提供的库。团队还评估了相比FP16、4-bit单元素量化工作时的性能,如下图所示:
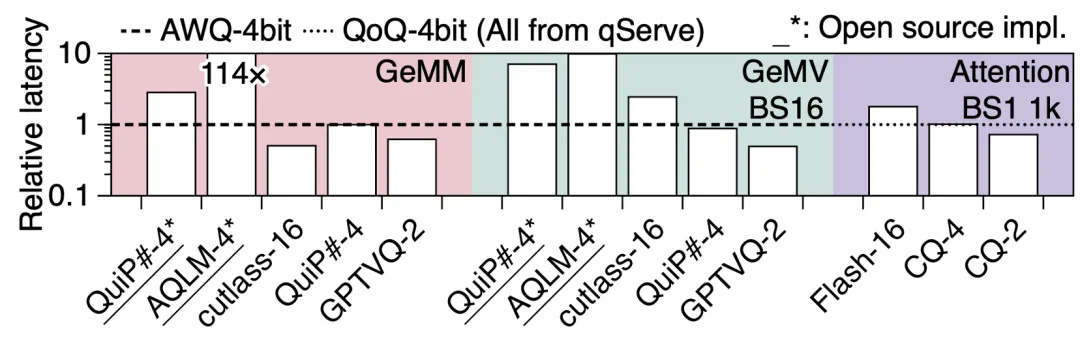
图4. 与逐元素量化方案的延迟对比
其中矩阵乘GeMM作为相对而言更为Compute-Bounded的算子,量化对其的优化有限,故性能劣于FP16。然而其在大模型推理中由于只存在于Prefilling阶段,占比较小,故影响也较小。除此之外,无论是GeMV还是Attention,团队的实现都显著优于FP16,相比4-bit单元素量化也能持平。而2-bit下,团队的实现优势明显,然而单元素量化在2-bit已经无法有效保持精度。
该工作提出的VQ-LLM能够将向量量化带来的压缩比反映到实际加速比。本论文一作为上海期智研究院实习生、上海交通大学博士生刘子汉,通讯作者为上海期智研究院PI、上海交通大学教授冷静文。
论文信息:
VQ-LLM: High-performance Code Generation for Vector Quantization Augmented LLM Inference, Zihan Liu, Xinhao Luo, Junxian Guo, Wentao Ni, Yangjie Zhou, Yue Guan, Cong Guo, Weihao Cui, Yu Feng, Minyi Guo, Yuhao Zhu, Minjia Zhang, Chen Jin, Jingwen Leng†, https://arxiv.org/abs/2503.02236, HPCA 2025.
基于数学自适应数值类型的大模型低比特量化
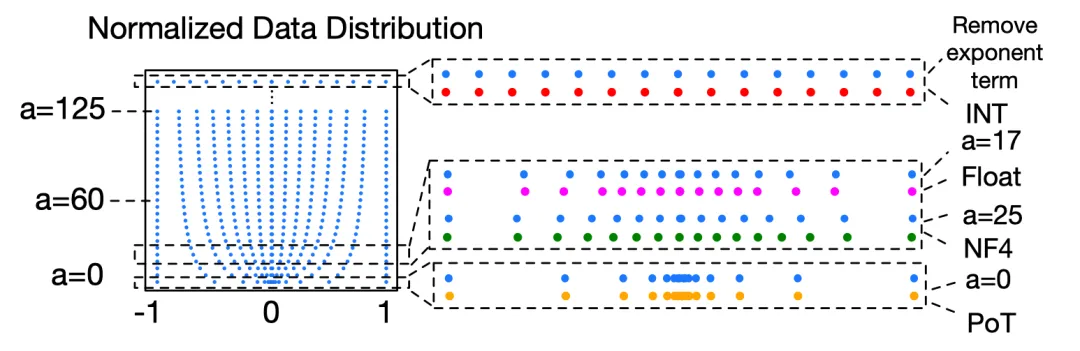
图5. 通过可调系数拟合多种低精度数值类型
随着主流大语言模型(如 LLaMA、GPT)参数规模的持续扩张,其推理过程对显存、带宽和计算资源提出了空前挑战。为了在保障精度的同时提升部署效率,低比特量化逐渐成为主流解决方案,广泛应用于模型权重和 KV 缓存压缩之中,有效缓解了内存带宽瓶颈并提升了系统吞吐率。
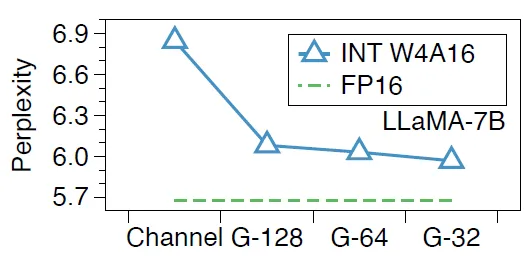
图6. 分组量化能够降低任务的困惑度分数
近年来兴起的分组量化(Group-wise Quantization)方法,以小组(如64个值)为粒度量化,通过更细粒度的压缩策略,有效提升精度与压缩率,逐步成为高性能推理的标准配置。然而,现有方法仍面临两大关键挑战:组内分布差异显著,固定数据类型适应性不足,以及KV缓存的动态特性使得量化效率低下。因此,如何高效完成 KV 缓存在解码阶段的分组量化,成为当前实时量化研究的核心技术难点。
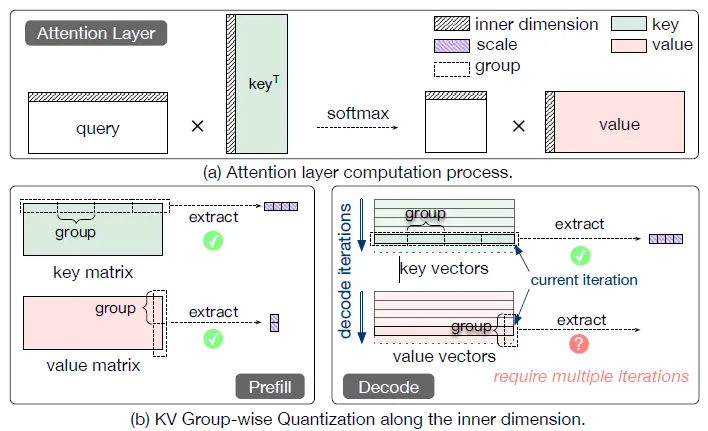
图7. 分组式K/V缓存量化的对比分析
为此,冷静文团队提出了数学自适应数值型(M-ANT)量化框架,结合软硬件协同优化,全面提升精度、延迟与能耗表现。该工作具有如下三大创新:
(1)数学表达驱动的数值类型映射机制
M-ANT 提出一种基于数学函数表达的统一编码框架,通过引入单一超参数 a来改变量化格点的数据分布。这种设计不仅能连续拟合 INT、NF、PoT、Float 等主流数值类型,还支持非均匀分布的精细建模。具体来说,不同的 a 值对应不同的动态范围和分布覆盖,使得每个分组能够根据实际的统计分布自适应选择最优的编码形式,显著提升量化精度,且无需复杂的查找表或特定解码器逻辑,保持了整数友好性和推理高效性。
(2)实时量化引擎支持KV缓存统一编码
面对 KV 缓存在解码阶段的动态生成特性,M-ANT 设计了一套双阶段(Two-Stage)量化机制:时间域缓冲 + 空间域处理。第一阶段以「窗口式累积策略」将V向量量化到INT8,随后缓存若干步内生成的 V 向量,使得每个分组可以获得完整的统计信息(如最大值、方差);第二阶段使用完整的统计进行将V向量从INT8量化到4比特M-ANT形式。该设计有效解决了LLM推理时难以获取V向量分组统计信息的问题。
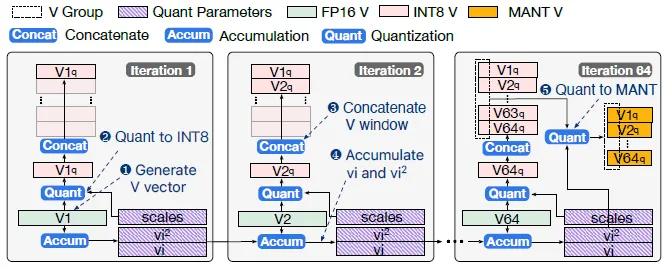
图8. V cache双阶段量化流程
(3)硬件友好的融合计算架构设计及数据流优化
在硬件层面,M-ANT 基于脉动阵列架构,重构数据路径以实现解码与计算的深度融合。核心优化在于数据流的路径融合与访存重构,即将非均匀编码的解码操作与后续乘累加运算紧耦合处理,避免传统「先解码后计算」所带来的访存瓶颈。系统在原有的 MAC(乘累加)阵列下方新增 SAC(缩放累加)路径,使得不同编码形式的张量在解码过程中直接参与主计算通路,显著减少中间存储和数据搬运。
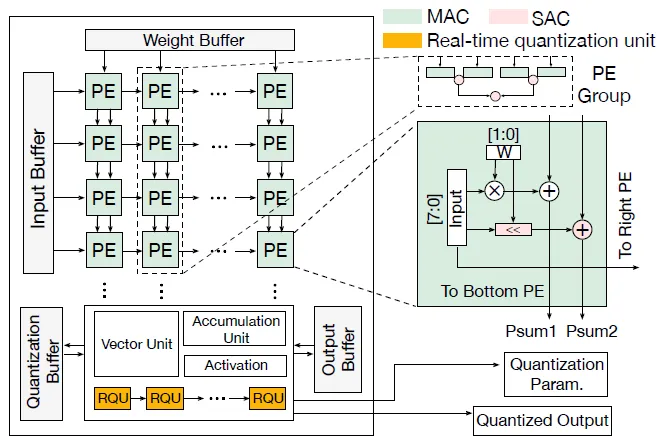
图9. 支持M-ANT解码与实时量化的硬件架构
最终,M-ANT在多种主流大模型(如LLaMA、OPT)上验证有效性,支持组级INT4量化,平均加速比达2.99×(最高4.46×),能耗降低2.81×(最高4.10×),同时保持与FP16接近的精度表现。
M-ANT是面向大模型的新型数学自适应数值类型,显著提升细粒度组量化在推理过程中的性能与灵活性。本论文一作为上海期智研究院实习生、上海交通大学博士生胡洧铭,通讯作者为上海期智研究院PI、上海交通大学教授冷静文。
论文信息:
M-ANT: Efficient Low-bit Group Quantization for LLMs via Mathematically Adaptive Numerical Type, Weiming Hu, Haoyan Zhang, Cong Guo, Yu Feng, Renyang Guan, Zhendong Hua, Zihan Liu, Yue Guan, Minyi Guo, Jingwen Leng†, https://arxiv.org/abs/2502.18755, HPCA 2025.







