
2025-04-28

Innovation Highlights
1. 高鸣宇提出针对动态神经网络的专用加速架构Adyna。该架构采用硬件-软件协同设计的思想,高效支持动态神经网络的推理执行。首先,Adyna利用统一的表示方法来涵盖大多数现有的动态神经网络模型,以实现通用设计。其次,Adyna采用动态感知的多核选择范式,其中数据流调度器根据动态尺寸值的分布做出资源分配决策,而硬件架构则保留多个预编译的核函数,以根据每个特定数据的动态尺寸选择最佳匹配的核函数执行。最后,Adyna利用高效核函数采样,精心选择要加载到硬件上的核函数集合。在各种动态神经网络模型上的评估表明,Adyna比当前最优的加速架构可达到平均1.57倍、最高2.32倍的性能提升。
Achievements Summary
动态神经网络专用加速架构—Adyna
与传统神经网络中静态的算子大小和模型结构不同,动态架构神经网络(简称动态神经网络)允许在运行时针对每个输入数据动态决定执行哪些计算,例如动态的算子数量、动态的算子形状、动态的数据处理路径等。著名的混合专家模型(MoE)就是一种动态神经网络。动态神经网络能够根据不同数据处理难度的差异来动态减少计算需求,在不牺牲模型精度的情况下节省不必要的计算。
由于动态神经网络通常将数据样本划分为更小的子集在模型的不同分支中执行,因此每个算子的计算负载会减少,适合令多个算子在空间上共享芯片资源。现有多租户(multi-tenant)神经网络加速器和多核(multi-tile)神经网络加速器具有这种潜力。然而,它们都缺乏某些关键特性,难以高效执行动态神经网络。
在本工作中,高鸣宇团队提出了Adyna,作为一种新颖的软硬件协同设计,用于高效支持动态神经网络推理。该工作在算法表示、数据流调度和硬件架构等多个层面做出了创新的贡献。
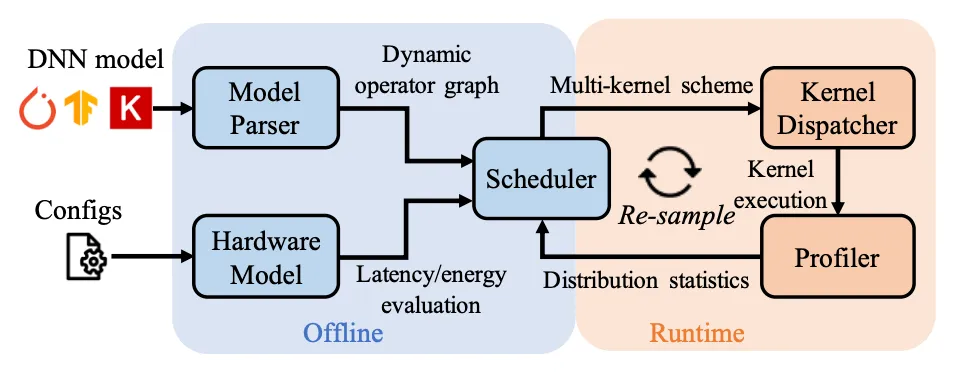
图1. Adyna技术概览及工作流程
首先,为了支持多样化的动态神经网络类型,Adyna提出了一个新颖的统一表示方法,能够涵盖几乎所有已知的动态神经网络模型,包括动态模型深度、动态算子大小和动态执行路径。其次,Adyna利用了一种动态可感知的数据流调度器,基于频率加权的方法,根据每个动态算子形状的期望值来分配资源。同时,Adyna还具有进一步的优化措施,可以减少运行时瞬时负载变化以及极少使用的算子的资源空闲。再次,在当前最优的多核架构的基础上,Adyna在每个加速核中保存多个针对不同动态大小优化的核函数实现,并根据实际大小动态选择最佳匹配的核函数执行。为了减少大量核函数实现占用的片上存储空间,Adyna采用了“模板+元数据”的方式,将核函数大小减少到仅128字节。Adyna还增强了片上互连,以支持动态数据路由和多核之间的同步。最后,Adyna调度器采用了新颖的核函数采样算法,有效地选择最有可能匹配实际执行分布的核函数子集,进一步限制了硬件上核函数的存储大小。
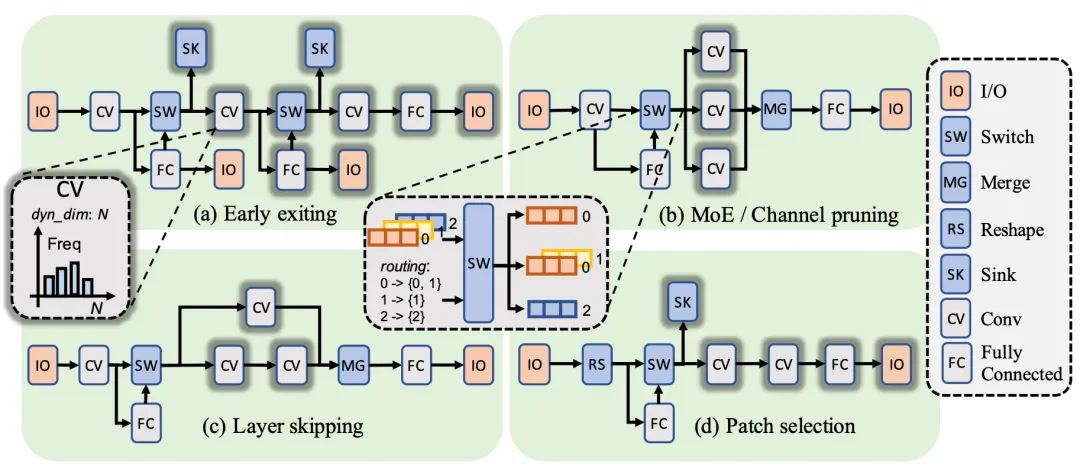
图2. Adyna所采用的统一的动态神经网络表示方法
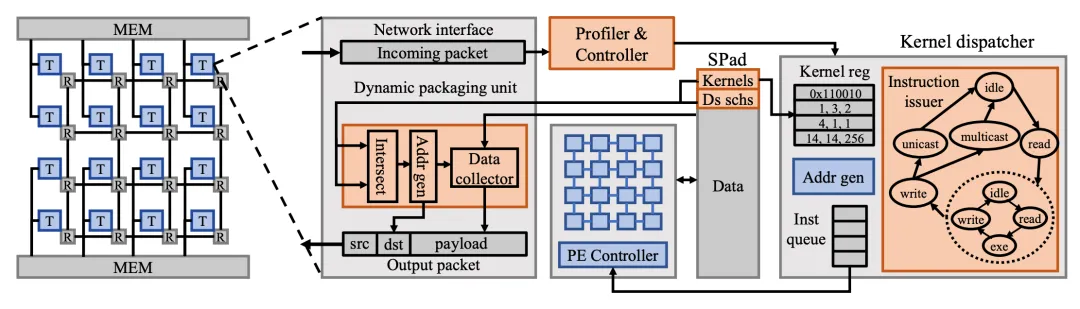
图3. Adyna的硬件架构
在具有四种动态行为的多种类型的动态神经网络上的评估结果表明,与多核和多租户架构相比,Adyna可实现平均1.70倍和1.57倍、最高2.32倍和2.01倍的性能提升。与理想情况相比,平均性能差距仅为13%。
本工作一作为清华大学博士生李之尧,通讯作者为上海期智研究院PI、清华大学副教授高鸣宇。共同作者为中国科学技术大学本科生杨博涵,加拿大多伦多大学博士生李佳翔,清华大学博士生陈泰杰、李欣桐。
论文信息:
Adyna: Accelerating Dynamic Neural Networks with Adaptive Scheduling, Zhiyao Li, Bohan Yang, Jiaxiang Li, Taijie Chen, Xintong Li, Mingyu Gao†, https://people.iiis.tsinghua.edu.cn/~gaomy/pubs/adyna.hpca25.pdf, HPCA 2025.
此外,高鸣宇教授还有三篇合作论文也收录于HPCA 2025,包括:
1. SoMA: Identifying, Exploring, and Understanding the DRAM Communication Scheduling Space for DNN Accelerators,
Jingwei Cai, Xuan Wang , Mingyu Gao, Sen Peng, Zijian Zhu , Yuchen Wei, Zuotong Wu , Kaisheng Ma, HPCA 2025, 面向神经网络专用加速器提出了优化的片外DRAM数据访问方式;
2. Lincoln: Real-Time 50~100B LLM Inference on Consumer Devices with LPDDR-Interfaced, Compute-Enabled Flash Memory, HPCA 2025, 在消费端设备上利用基于闪存的存算一体架构,对人工智能大模型进行加速;
3. EFFACT: A Highly Efficient Full-Stack FHE Acceleration Platform,Yi Huang, Xinsheng Gong, Xiangyu Kong, Dibei Chen , Jianfeng Zhu , Wenping Zhu, Liangwei Li , Mingyu Gao , Aoyang Zhang , Shaojun Wei, Leibo Liu, HPCA 2025, 提出了一种高效的全栈式全同态加密加速平台。







