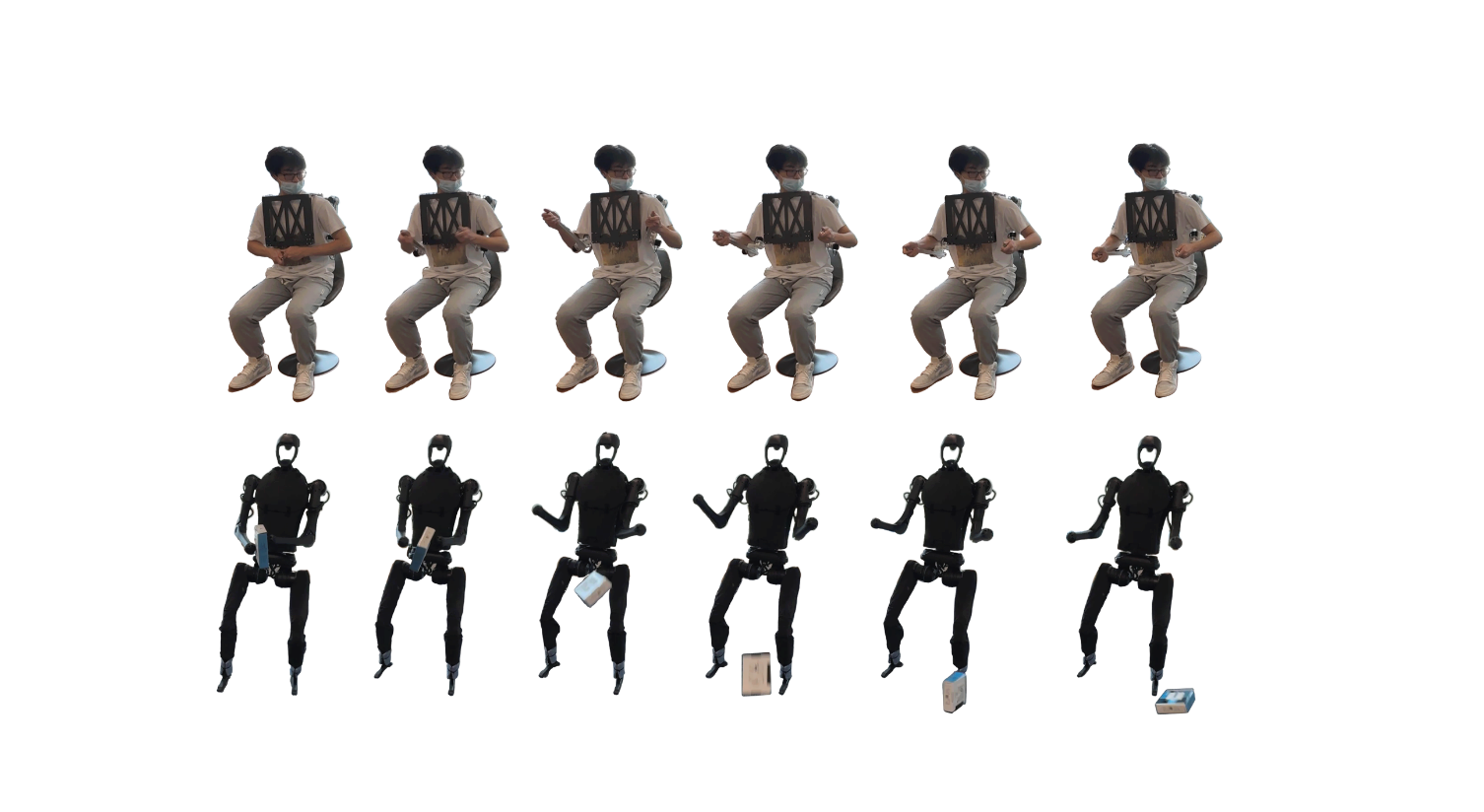上海期智研究院PI,清华大学交叉信息研究院助理教授。
博士毕业于麻省理工学院MIT,后于谷歌无人车项目Waymo担任研究科学家。其研究领域涵盖多模态学习,自动驾驶和机器人。提出了自动驾驶中一系列框架型的工作,为行业大多数公司所使用或借鉴。曾获智能机器人顶会CoRL2023最佳系统论文提名Top3,ICCP最佳论文奖,福布斯中国30Under30。曾担任ICLR大会联席主席,NeuRIPS/ICCV领域主席,曾获得世界人工智能大会最高荣誉“SAIL之星奖”。
个人荣誉:
福布斯中国30位30岁以下精英(科学榜,2020年)
Snap Research Fellowship 2019
ICCP最佳论文奖 2015
MIT Rohsenow Fellowship 2013
多模态学习:贯通图像、文本、声音、视频等模态信号的多模态生成模型
自动驾驶:下一代以视觉为中心、数据驱动的自动驾驶技术
机器人学:视觉驱动的足式机器人导航和敏捷运动
成果15:长序列流式三维重建(2025年度)
赵行团队推出LONG3R:一款专为长序列流式3D场景重建设计的创新模型。LONG3R突破了现有方法在实时处理长序列输入图像时的瓶颈。LONG3R提出的3D时空记忆机制,能够动态修剪冗余空间信息,显著提升推理效率。同时,LONG3R引入记忆门控机制,智能过滤关键记忆,并结合新观测数据,通过双源精细解码器进行粗到细的优化处理,全面提升长序列的重建效果。为了进一步提升训练效率和模型表现,LONG3R采用了两阶段课程训练策略,针对不同能力进行优化。实验结果表明,LONG3R在多个数据集的长序列流式重建任务中,显著超越现有最先进方法,并能够保持实时推理速度。
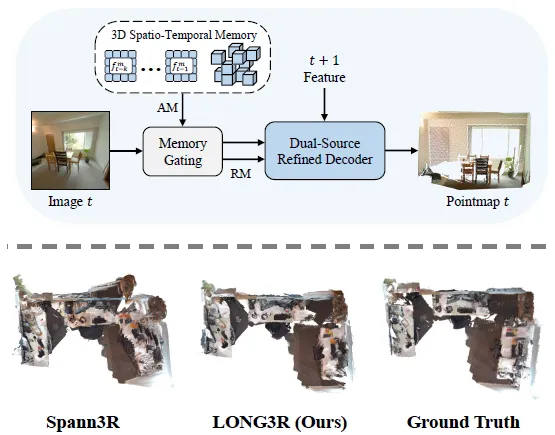
图. LONG3R框架及3D重建效果定性对比
论文信息:
https://arxiv.org/pdf/2507.18255
LONG3R: Long Sequence Streaming 3D Reconstruction, Zhuoguang Chen* Minghui Qin*, Tianyuan Yuan*, Zhe Liu, Hang Zhao†,ICCV 2025.
-----------------------------------------------------------------------------------------------------------------------------
成果14:基于高斯泼溅的纯视觉规模化占据栅格重建(2025年度)
赵行团队提出占据栅格自动标注新范式GS-Occ3D,旨在解决目前主流的占据栅格标注严重依赖激光雷达、成本高昂、难以扩展、无法利用数量更庞大的消费级车辆的众包数据的问题,具有语义丰富且方便获取、成本效益高、可规模化等优点。该方法基于八叉树高斯面元场景表征,将场景解耦成静态背景、地面和动态物体并高效重建,在Waymo数据集实现了SOTA的几何重建结果,超过激光雷达监督的基线模型。该框架首次用纯视觉方法重建了整个 Waymo 数据集,在Occ3D-nuScenes数据集上展示了更优的零样本泛化能力,具备高度的可扩展性与可靠性。
本论文共同一作为研究院实习生叶柏均,通讯作者为研究院PI赵行。
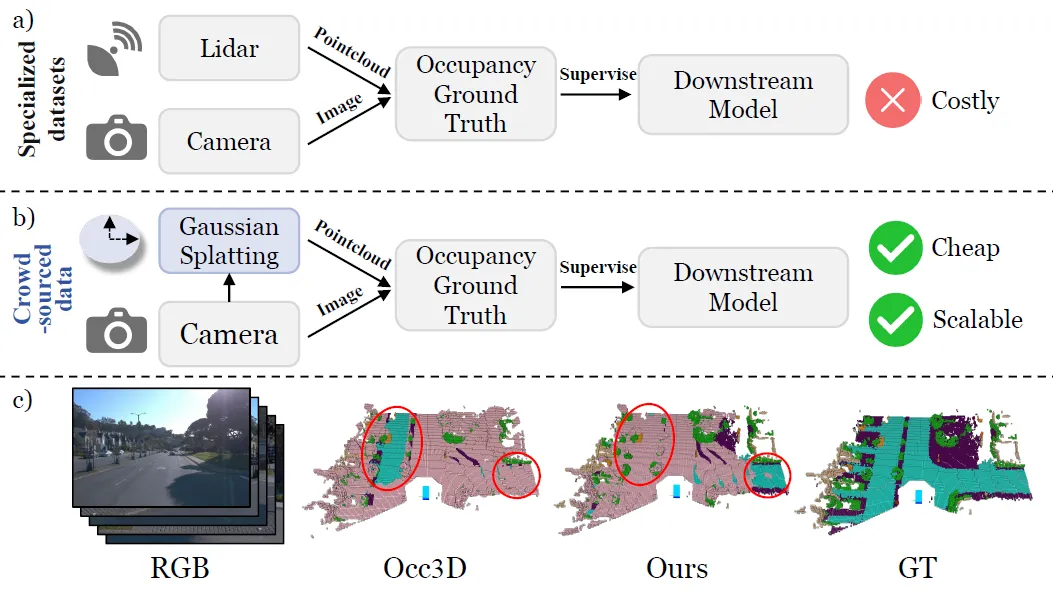
图. 占据栅格自动标注范式对比
论文信息:
https://arxiv.org/pdf/2507.19451
GS-Occ3D: Scaling Vision-only Occupancy Reconstruction with Gaussian Splatting, Baijun Ye*, Minghui Qin*, Saining Zhang*, Moonjun Goon, Shaoting Zhu, Zebang Shen, Luan Zhang, Lu Zhang, Hao Zhao, Hang Zhao†,ICCV 2025.
------------------------------------------------------------------------------------------------------------------------------
成果13:灵动机器狗:四足机器人高动态精确运动学习(2025年度)
赵行团队提出 MoE-Loco,一种基于混合专家(MoE)架构的四足机器人多任务运动控制框架,旨在解决多任务强化学习中梯度冲突导致的训练效率与性能瓶颈问题。该框架可通过单一策略,使四足机器人同时应对杆、坑、楼梯、斜坡等复杂地形,并实现四足与双足步态的切换。
其采用两阶段训练策略:第一阶段结合特权信息与本体感受训练策略,第二阶段仅依赖本体感受适配实际场景;门控网络协调多个专家模块,使神经网络专家实现专业化。在 IsaacGym 仿真与 Unitree Go2 实机实验中,MoE-Loco 的任务成功率、运动效率显著优于无 MoE 架构及 RMA 等基线方法,且有效缓解梯度冲突。此外,该框架可通过调整专家权重组合新技能(如运球步态),提升了机器人运动的鲁棒性与适应性。未来计划融合视觉传感器进一步扩展其应用场景。
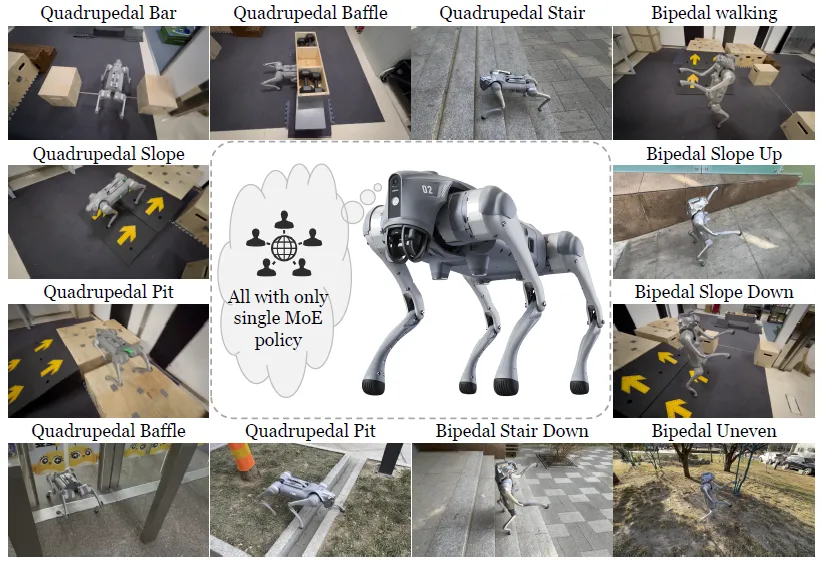
图. MoE-Loco:四足机器人可穿越各种复杂地形并执行不同运动模式
论文信息:
https://arxiv.org/pdf/2503.08564
MoE-Loco: Leveraging Mixture of Experts for Multi-Task Locomotion, Runhan Huang*, Shaoting Zhu*, Yilun Du, Hang Zhao†,IROS 2025.
------------------------------------------------------------------------------------------------------------------------------
成果12:MoE-Loco:面向多任务运动控制的混合专家框架(2025年度)
赵行团队实现了基于强化学习的感知-控制解耦系统,探索四足机器人在高动态运动中与外界物体交互的精确性。研究团队在四足机器人前端安装了形似狗嘴的被动夹持器,使机器人能够完成跳跃捕捉小型目标物体的任务。通过设计奖励函数、课程学习和动态目标仿真等技术,提升了机器人的性能表现。实验结果表明,机器人能够追踪速度高达3米/秒的空中移动球体,在真实环境中可捕捉0.8米高度的目标。研究团队对目标位置的感知噪声以及目标绝对高度等影响因素进行了实验分析,为四足机器人动态物体操作领域提供了重要见解。

图. Playful DoggyBot:能够完成跃起捕获小型目标物体的高动态任务
论文信息:
http://arxiv.org/pdf/2409.19920
Playful DoggyBot: Learning Agile and Precise Quadrupedal Locomotion, Xin Duan,Ziwen Zhuang,Hang Zhao†,Sören Schwertfeger†,IROS 2025.
------------------------------------------------------------------------------------------------------------------------------
成果11:拥抱碰撞,人形机器人影子跟随,以及任意身体部位的环境碰撞(2025年度)
赵行团队提出一种人形机器人全身动作控制框架,突破了传统研究仅将机器人视为“双足移动平台”的局限。人类在日常中常通过全身与环境互动,如坐下、起身或翻滚,而现有方法在应对不可预测的接触序列和复杂动作时存在困难。模型预测控制难以实时规划,强化学习则依赖高性能物理模拟和简化碰撞检测,同时缺乏大幅躯干运动数据也增加了设计难度。
该团队提出的框架可接收离散动作指令,并实时控制机器人电机。依托GPU加速模拟器,他们训练出全身控制策略,能在现实环境中稳定运行,即便面对随机接触、大幅度旋转或不合理动作指令,亦能保持良好表现。此成果为人形机器人在复杂环境中的应用奠定了重要基础。
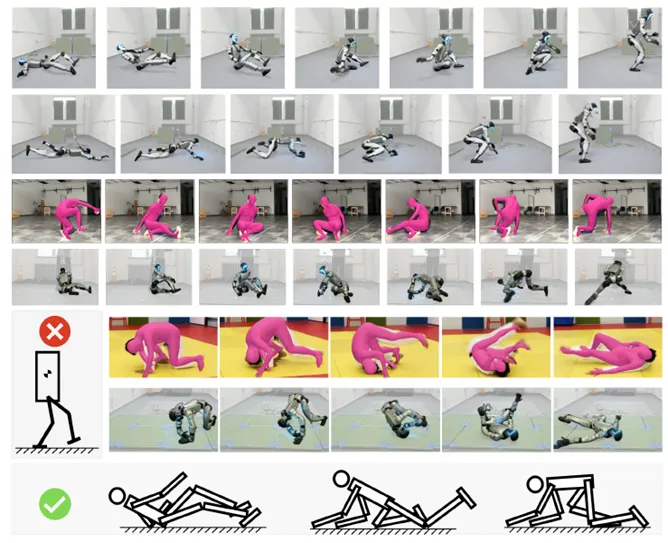
图. 统一的人形机器人运动接口与零样本仿真到现实的强化学习框架
论文信息:
https://openreview.net/pdf?id=JibqR9sEdW
Embrace Contacts: Humanoid Shadowing with Full Body Ground Contacts, Ziwen Zhuang, Hang Zhao†,CoRL 2025.
------------------------------------------------------------------------------------------------------------------------------
成果10:鲁棒行走的机器人:学习灵巧跨越微型陷阱技能(2025年度)
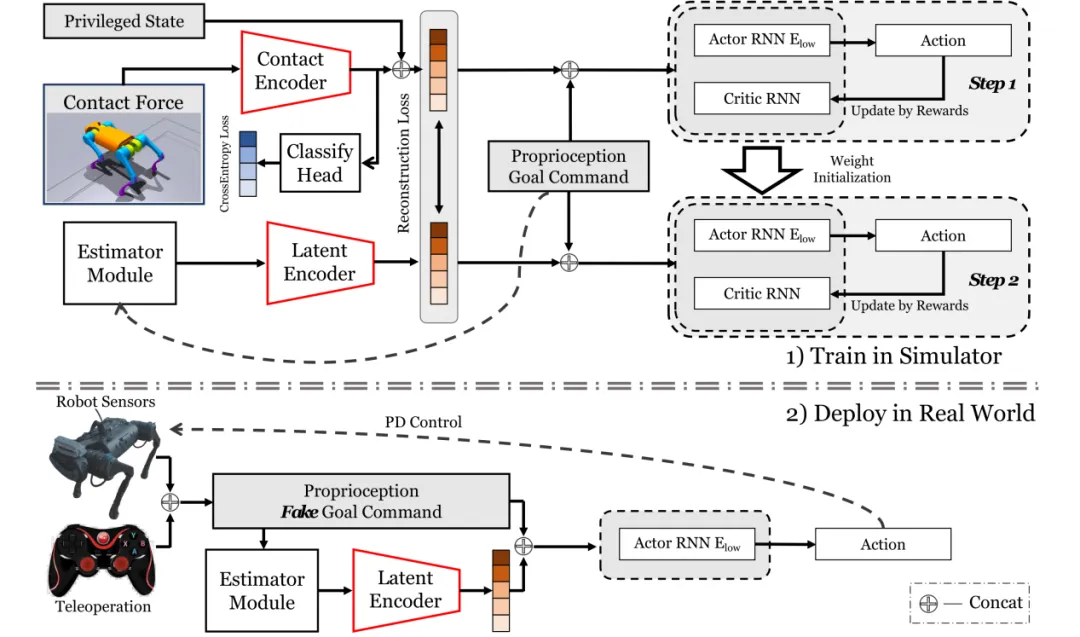
图. (上) Robust Robot Walker在仿真中的两步训练框架
(下) 训练所得策略模型在真实机器人中的部署
赵行团队提出了一套围绕接触力建模与本体控制融合的强化学习算法,突破了传统依赖外部感知的四足机器人越障范式。在算法设计上,团队构建了一个两阶段训练架构,在初期引入特权状态与接触力进行策略初始化,后期转向纯本体感知控制。该架构利用本体感知估计和预测特权状态和接触力,形成了显式+隐式状态估计的融合机制,显著提升了机器人识别和应对复杂接触场景的能力。此种编码策略不仅提升了策略泛化性,还有效缓解了仿真到现实的迁移问题,尤其是在存在摩擦、阻尼等外部环境偏差的情况下依然能保持稳定运行。
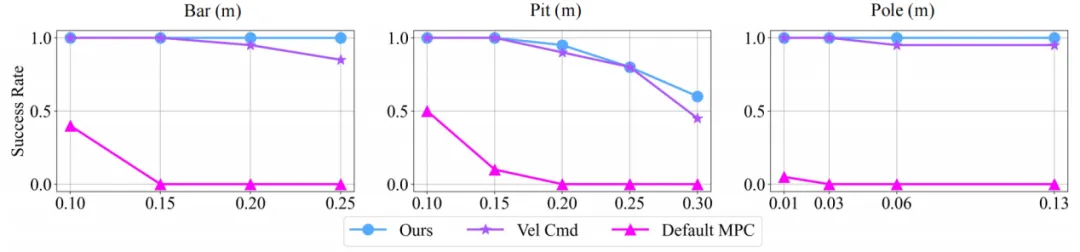
图. 真机实验成功率曲线
在理论建模方面,团队对本体信息驱动下的目标追踪任务进行了结构性重构。团队将传统的速度指令控制转换为“伪目标指令”驱动的目标位置追踪,从而实现在无定位系统条件下的近似全向控制。同时,围绕该任务重新设计了多个密集型奖励函数,如朝向奖励、目标接近度、静止奖励等,不仅优化了策略收敛性,也自然地训练出了多样化运动策略。团队提出的训练方法使机器人在面对不同障碍组合时能够自主调整步态与策略,展现出极高的适应性。
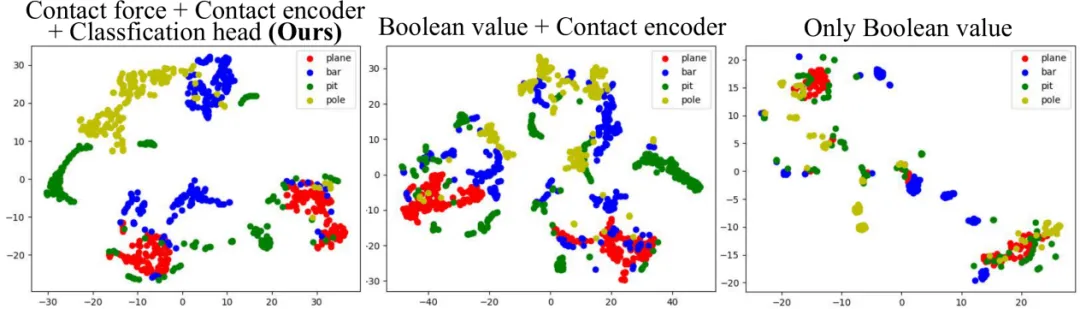
图.隐空间T-分布领域嵌入(t-sne)分布图
团队主要解决了两个长期存在的挑战:一是外部感知在实际场景中对细微障碍物识别不准的问题;二是控制策略在无精确状态估计条件下无法稳定部署的问题。通过引入基于接触力的隐状态估计器与融合表示空间,机器人不再依赖色彩图像或深度图像即可“感知”地形类型,并自动调整运动行为。此外,训练策略具备良好的可迁移性,能够在不同障碍密度、障碍组合顺序甚至完全未见过的障碍构型下稳定运行。
该工作的最大价值在于其面向真实部署的通用性与实用性。在不依赖任何视觉、定位、运动捕捉系统的前提下,该策略实现了在真实世界中快速部署、零样本推理与可控移动。相比传统方法,所需传感器更少、部署成本更低,具有显著的工程可落地优势。此外,该工作也首次系统性地定义与建立了“微型陷阱”任务与评测标准(Tiny Trap Benchmark),填补了四足机器人越障领域在“细节级障碍”层面的研究空白。

图. “微型陷阱”任务与评测标准。四足机器人从跑道左侧出发,跨越多种障碍物最终到达右侧的目标点
------------------------------------------------------------------------------------------------------------------------------
成果9:基于视觉-语言模型的机器人空间感知和地形跨越系统—SARO(2025年度)

当前四足机器人在复杂三维地形中的自主导航仍面临诸多挑战,特别是在跨越楼梯、坡道、缺口等不规则地形时,传统方法难以在感知、决策与运动控制间协同处理三维空间中的运动规划任务。一方面,已有视觉-语言模型(VLM)具备良好的常识推理与视觉感知能力,但难以直接应用于连续控制任务;另一方面,低层控制策略往往缺乏对环境语义的理解和任务分解能力,导致系统整体的适应性和鲁棒性不足。
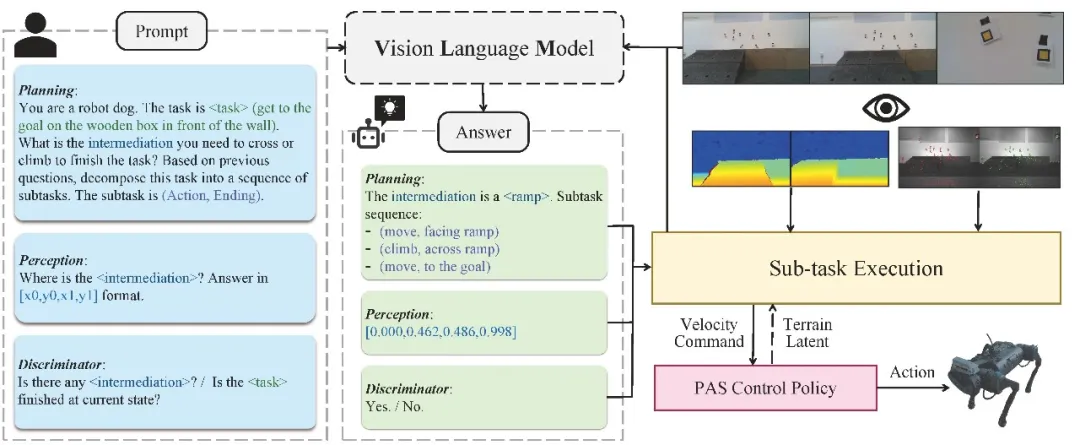
图. SARO系统框架总览图
针对上述问题,赵行团队提出SARO(Space-Aware Robot System for Terrain Crossing),该系统首次将预训练VLM引入四足机器人3D导航任务,有效打通了高层语言推理与低层动作控制之间的链路。具体而言,SARO系统利用VLM从单目图像中进行零样本推理的任务理解实现高层控制。系统通过生成“动作-结束状态”对子序列和双判别机制实现闭环控制,实现了语义驱动的子任务稳定执行。同时,团队创新性地提出概率退火选择(Probability Annealing Selection, PAS)方法实现低层控制。通过两阶段训练替代传统强化学习方式,最终策略仅依赖本体感知输入即可适应复杂地形,显著提升了系统在真实场景中的泛化能力与稳定性。
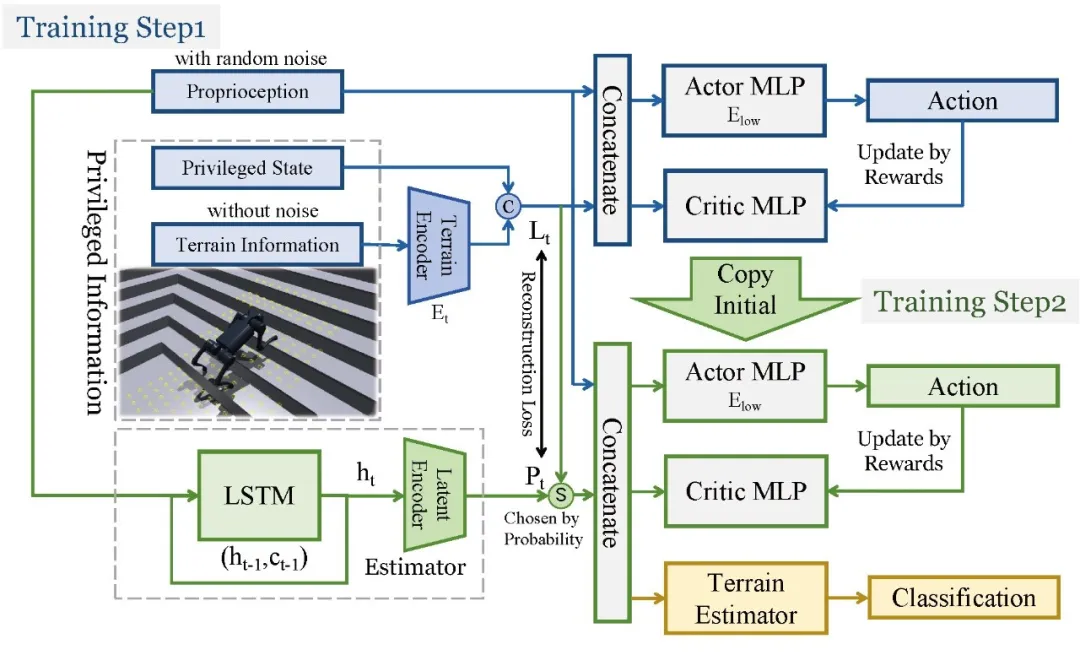
图 概率退火选择策略低层控制算法总览图
在多种典型地形(如楼梯、斜坡、缺口、门框)组成的复杂场景中,SARO系统显著优于现有基线方法(如ViNT、NoMaD、LSTM等),例如在楼梯跨越任务中达到88%的成功率。更重要的是,SARO系统具备良好的现实部署能力,可在未见过的户外自然地形中保持稳定表现。此外,PAS控制策略在仿真环境中以85.3%的平均成功率显著优于RMA、IL等方法,并在真实世界的草地、碎石坡等地形中实现95%以上的高通过率,展现出极强的实用潜力。
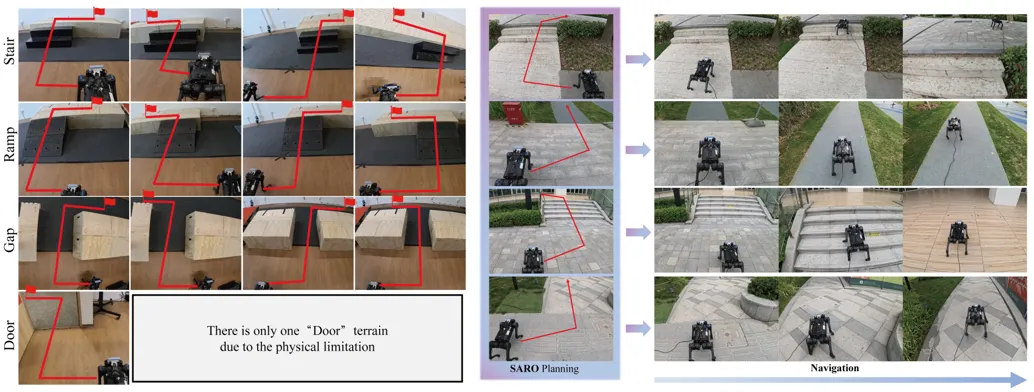
图. 在室内与室外多种地形上三维导航实验结果
------------------------------------------------------------------------------------------------------------------------------
成果8:用于自动驾驶运动规划泛化的专家混合模型扩展(STR2)(2025年度)
在自动驾驶运动规划领域,如何在复杂的城市道路场景和长尾少样本场景下保持规划器的鲁棒与泛化,一直是业内难题。传统的基于规则或优化的规划方法需要工程师手动设计代价函数,以平衡“舒适”“安全”“效率”等多重目标,往往在实际复杂路况中难以兼顾;而基于强化学习的规划器虽然具备一定的泛化潜力,却面临仿真到现实(sim-to-real)的巨大差距、训练成本高昂的挑战导致在实际应用中难以大规模落地应用。近年来,随着大规模驾驶数据的积累,自监督的模仿学习为运动规划提供了新的思路,但如何避免分布漂移与奖励冲突导致的性能下降,仍需在模型和训练范式上做出改进。
赵行团队率先引入了混合专家(MoE)架构的STR2方法,以解决自动驾驶运动规划领域,如何在复杂的城市道路场景和长尾少样本场景下保持规划器的鲁棒与泛化这一困扰业内多年的难题。本研究将驾驶轨迹预测与运动规划视作一个自回归序列建模问题:给定过去两秒的环境观测(包括道路几何、红绿灯状态、周围车辆和行人的位置等),通过使用了MoE的Transformer 架构直接预测未来八秒的最优轨迹,实现对复杂动态场景的预测与规划。这一思路与语言模型类似,利用 Transformer 在建模长序列依赖关系上的天然优势,从而减少对手工设计的依赖。为了在大规模数据上实现高效表达,STR2 首先将多模态交通信息通过 Rasterization 处理成两个尺度(近场与远场)的栅格图,每个栅格图由 34 通道的二值占用图组成,分别代表车道线、交通标志、动态障碍物等要素,并通过一个 12 层堆叠的 Vision Transformer 对这些多尺度栅格图进行编码,将其切分为 16×16 的 Patch 并映射为序列输入,再与车辆历史运动状态特征一并输入解码器。
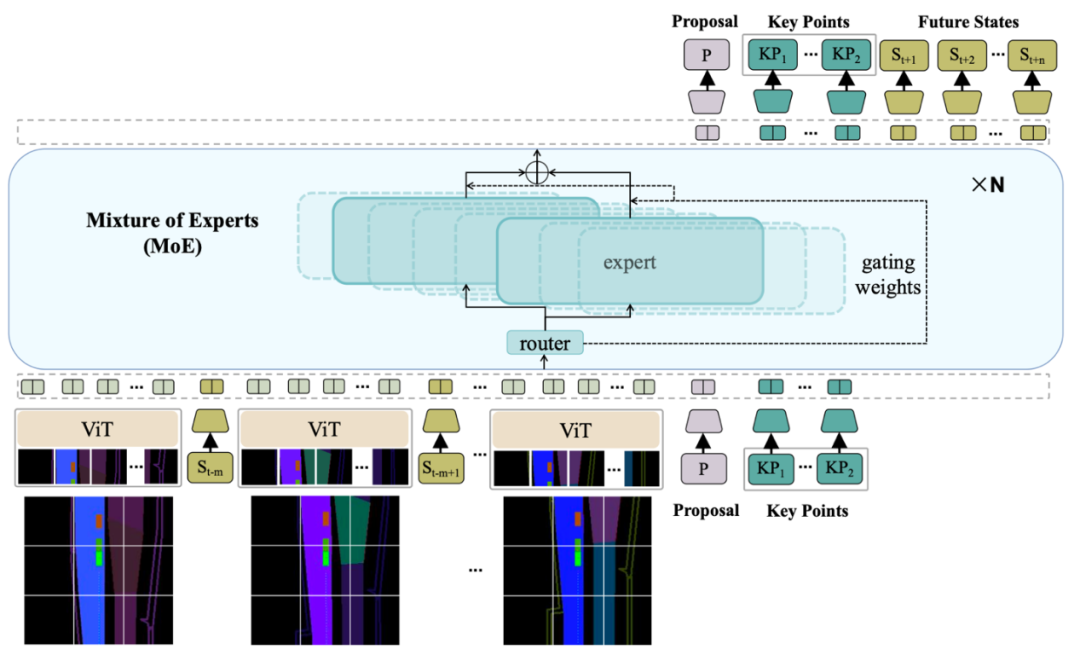
图. STR2 模型结构概览—包含多尺度栅格化 ViT 编码器、专家路由层、Proposal 分类嵌入与 Autoregressive 解码
在解码阶段,团队引入了混合专家(MoE)架构,以解决纯 Transformer 在面对多目标冲突时可能出现的奖励平衡问题。在每一层的 Transformer 中,基于门控路由机制,根据当前样本的场景特征,将不同的奖励(例如对碰撞风险的避开、对前进效率的追求、对车道保持的遵守等)自动分发给若干专家网络,让每个专家在其负责的子任务上专注学习。这种设计一方面避免了普通单一网络在多重目标下出现的模态崩塌,另一方面通过专家并行与高效的 Flash Attention 技术,使得在 8 张 H100 GPU 上训练数十亿参数规模的模型成为可能。为了进一步缓解在连续轨迹空间下的回归难度,我们在自回归序列中插入了 Proposal 分类嵌入,即通过对 70 万条历史轨迹进行 K-Means 聚类得到 512 个典型轨迹原型(Proposal),网络首先预测出轨迹落入哪个原型类别,再基于该原型生成精细的连续关键点。此种先分类后回归的设计有效减少了曲率预测的崩塌风险,使输出轨迹更加平滑合理。与以往需要额外引入强化学习、逆向强化学习或对比学习等多阶段训练范式相比,STR2 仅依靠自监督地拟合专家示例,在一个阶段内完成训练,简化了流程并大幅降低训练成本。训练过程中,我们使用 Cosine-Restart 学习率调度、bfloat16 精度训练,以及多尺度环境输入,使得模型能够快速收敛并具备良好的泛化能力。
在实验设计方面,团队首先在 NuPlan 数据集上构建了大规模训练集:去除静止状态后,提取出超过 700 万条有效驾驶场景作为训练样本;测试阶段,团队从 NuPlan 的验证集和测试集中各随机抽取 4000 条场景,构成 Val4k 与 Test4k 两个基准测试集;同时,为了考察模型在少样本与零样本场景下的表现,团队选取了 Val14(14 万条更具挑战性的场景)、TestHard(包含复杂城市交叉路口与动态障碍物)以及通过场景合成技术生成的 InterPlan(施工区、碰撞现场等全新环境)。团队在开环(Open-Loop)设置下采用 OLS(Open-Loop Score)、8sADE(8 秒平均位移误差)、8sFDE(8 秒最终位移误差)等指标进行评测;在闭环(Closed-Loop)仿真中,则分别在非反应式(Non-Reactive)与反应式(Reactive)两种模式下评定碰撞率、车道合规度、限速合规度和时间到碰撞(TTC)等综合分数。除此之外,为了验证 STR2 在产业级数据上的可伸缩性,团队还在 LiAuto 自研数据集中开展了扩展实验:该数据集覆盖 70 万车次、1 亿条驾驶场景,团队针对不同的数据量级(百万级、千万级、亿级)以及不同模型参数规模(1 亿、3 亿参数)进行训练,并记录测试损失随数据量与参数量变化的幂律关系。
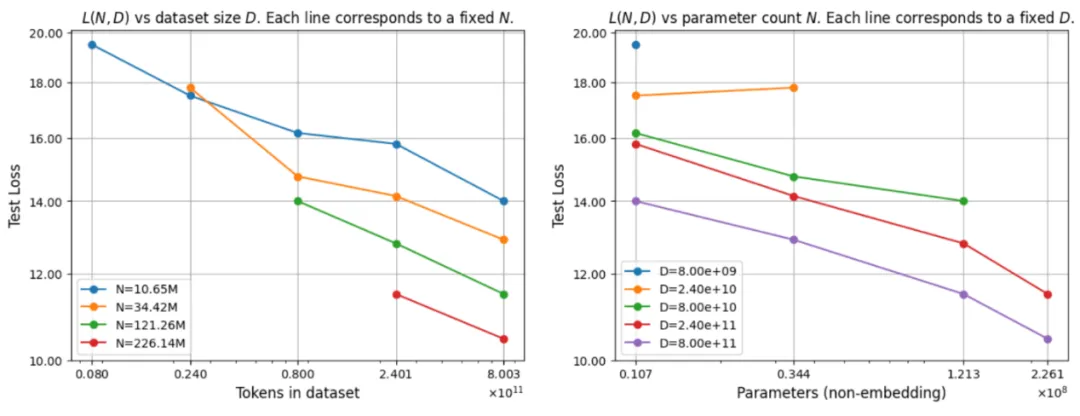
图.STR2在不同尺度的模型大小、计算资源以及数据量大小上的泛化性能展示
所有实验结果表明,STR2 在 NuPlan 的 Val4k、Test4k 以及 Val14 上,无论是 100M、800M 还是 1B 参数规模的模型,都在 OLS、8sADE、8sFDE 等开环指标上取得了优异成绩;在 Val14 与 TestHard 中,STR2 相较于先前方法(如 PDM-Hybrid、PlanTF、DTPP、GameFormer 等)的性能下降幅度更小,尤其在零样本合成场景(InterPlan)中表现出色,展示了对分布漂移的极强抗性。在闭环仿真中,无论是非反应式还是反应式设置,STR2 都获得了比现有方法更高的综合评分,而那些在反应式仿真下性能下降明显的方法,往往是由于过度拟合训练示例导致对新环境的鲁棒性不足。值得注意的是,在 LiAuto 产业级数据集上进行的可伸缩性实验中,STR2 在不同数据与参数配置下的测试损失都呈现对数线性下降趋势,验证了 MoE-Transformer 在真实工业环境中的有效性与可扩展性。
------------------------------------------------------------------------------------------------------------------------------
成果7:人形机器人跑酷(2024年度)

自从四足机器人的高动态强化学习让四足机器人的运动能力和通过性远超传统轮式机器人,人形机器人虽然有各种各样的硬件被设计制造了出来,但是运动控制算法大多局限在平地或者平缓的小台阶范围。这因为之前的强化学习算法大多依赖一个预先设定好的平地行走的动作参考,或者手动设计平地行走的关键运动学参数。这些方法逼迫双足机器人在任何需要移动的时候都必须抬脚,并且需要设计新的参考动作才能完成更加复杂的移动通过任务。赵行团队提出让人形机器人的移动,可以像最简单的训练机器狗一样,并且可以结合机载视觉系统,让人形机器人通过极度复杂,甚至不连续的地形。
团队创新借鉴了四足机器人上常用的分型噪声生成粗糙的地形,加上基础的强化学习奖励函数,让人形机器人能够自主产生稳定性走的步态,从而省去了设计针对某种机器人型号的动作参考的巨大工作量,让人形机器人的移动算法回归简单的实现方式。

图1. 用Perlin Noise在不同地形上产生粗糙的表面,用scan dot作为expert policy对环境感知的方法
此外,团队还验证了人形机器人在移动操作中的可能性。即使本次工作的神经网络是训练用于同时控制上肢和下肢,在复写上肢动作后,下肢仍然能够成功的保持平衡,并且根据遥操作指令准确执行上肢动作。为进行复杂的地形移动同时上肢进行操作的需求提供了可行性参考。
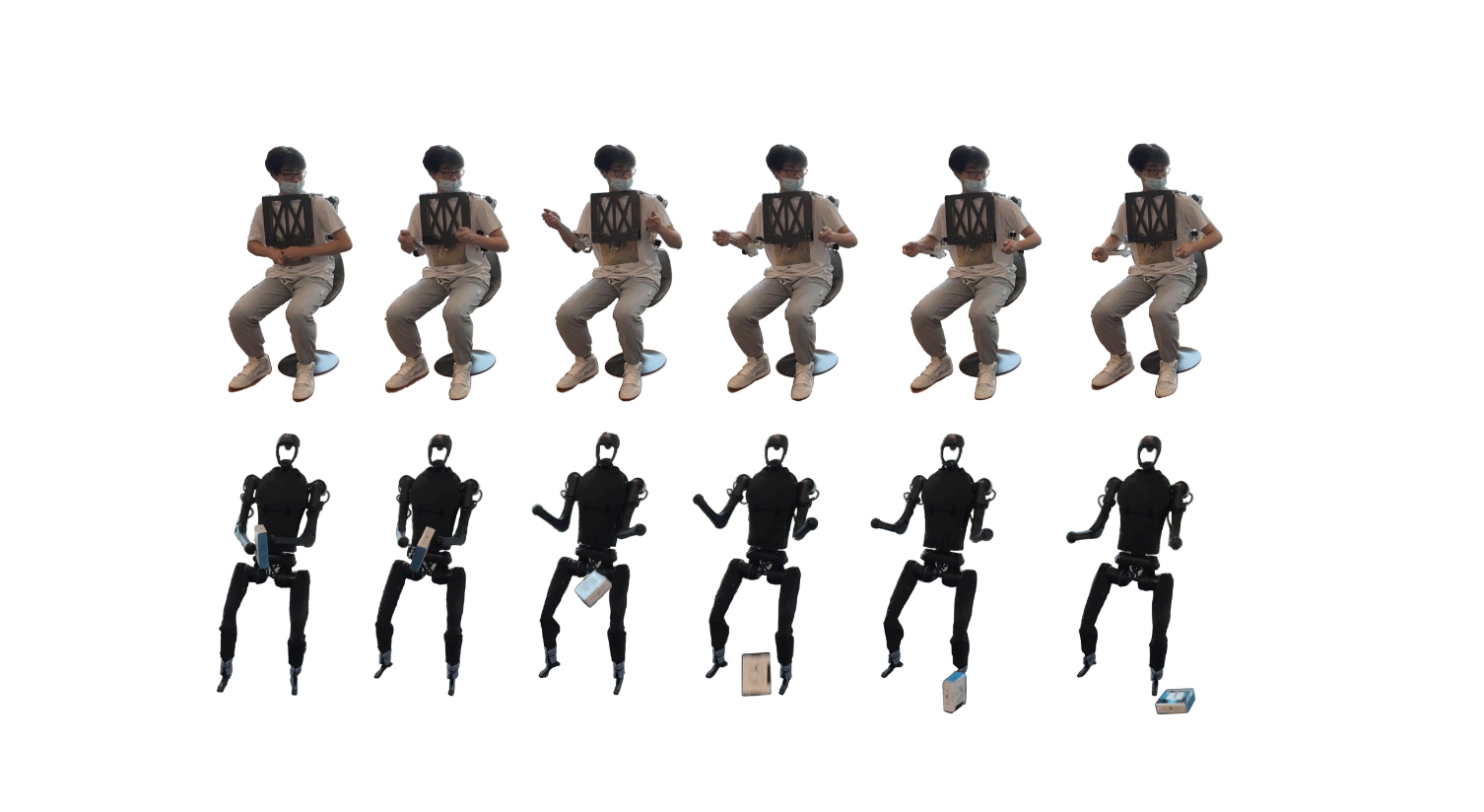
图2. 使用远程操作设置覆盖跑酷策略的动作
该研究推动了人形机器人在敏捷性、自主性和多任务能力方面的发展,为未来人形机器人在搜索救援、娱乐表演甚至日常生活中的应用奠定了基础。本论文一作为研究院实习生、清华大学交叉信息院博士生庄子文,通讯作者为清华大学交叉信息院助理教授赵行。共同作者为研究院实习生、上海科技大学本科生姚屾喆。
论文信息:Humanoid Parkour Learning, Ziwen Zhuang, Shenzhe Yao, Hang Zhao†, https://openreview.net/forum?id=fs7ia3FqUM, CoRL 2024.
------------------------------------------------------------------------------------------------------------------------------
成果6:PreSight:利用神经辐射场先验帮助自动驾驶场景的在线感知(2024年度)
今天的自动驾驶系统通常仅依靠在线传感器数据实现实时环境感知,而缺乏高效地利用过去观测数据的手段。与之相比,人类驾驶员在开车时会记住自己所开过的路段,在熟悉的道路上越开越好。为此,赵行团队设计了新的感知框架PreSight,通过构建城市级神经辐射场(NeRF),对过去的观测数据加以利用,重建城市级先验知识,增强下次经过同一路段时在线感知模型的表现。
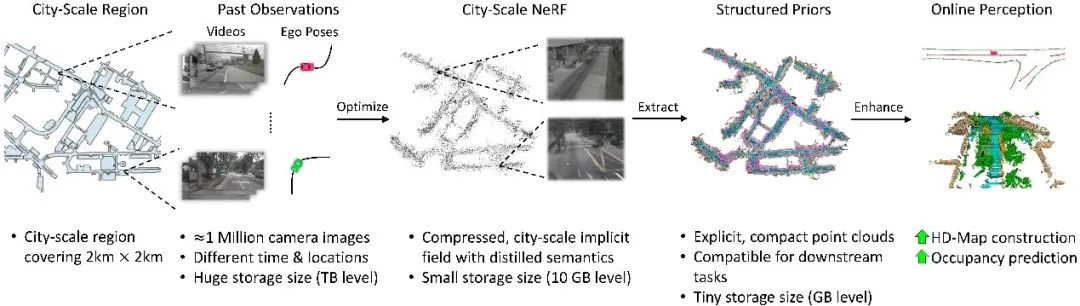
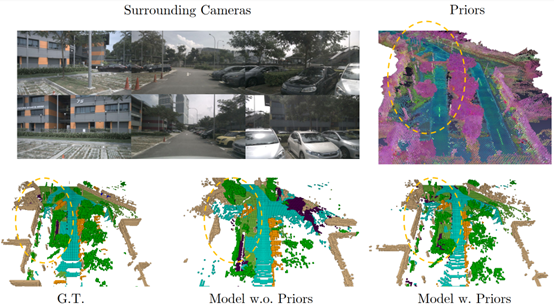
图1. PreSight方法概览
团队首先提出分块重建的思路,从而实现使用百万数量级图片构建数公里级的城市级NeRF。引入基础视觉模型DINO的知识,构建包含可泛化语义信息的场景先验。设计了一种即插即用的融合模块,可以有效地将构建好的场景先验和在线观测进行融合,能够与任意一种基于BEV的在线感知进行组合,提升其感知能力。最后,在nuScenes数据集上设计实验,证明了该方法能在局部高清地图感知、占据栅格 (Occupancy) 预测任务上有效提升模型表现。
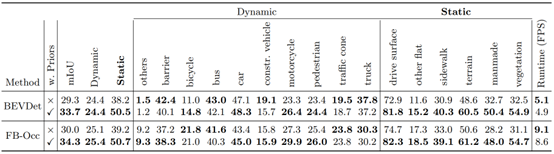
图2. PreSight对Occupancy预测任务的提升
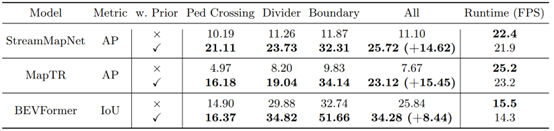
图3. PreSight对局部高清地图感知任务的提升
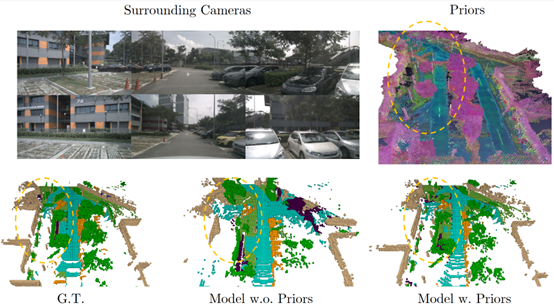
图4. PreSight对环境几何信息的精确重建帮助在线感知
PreSight框架首次提出了使用过去观测信息重建可泛化的城市级先验,为解决自动驾驶在线感知难的问题提供了新的思路,具有重要的理论和实践价值。
论文信息:PreSight: Enhancing Autonomous Vehicle Perception with City-Scale NeRF Priors, Tianyuan Yuan, Yucheng Mao, Jiawei Yang, Yicheng Liu, Yue Wang, Hang Zhao†, https://arxiv.org/abs/2403.09079, ECCV 2024
------------------------------------------------------------------------------------------------------------------------------
成果5:视觉为中心的自动驾驶技术(2024年度)
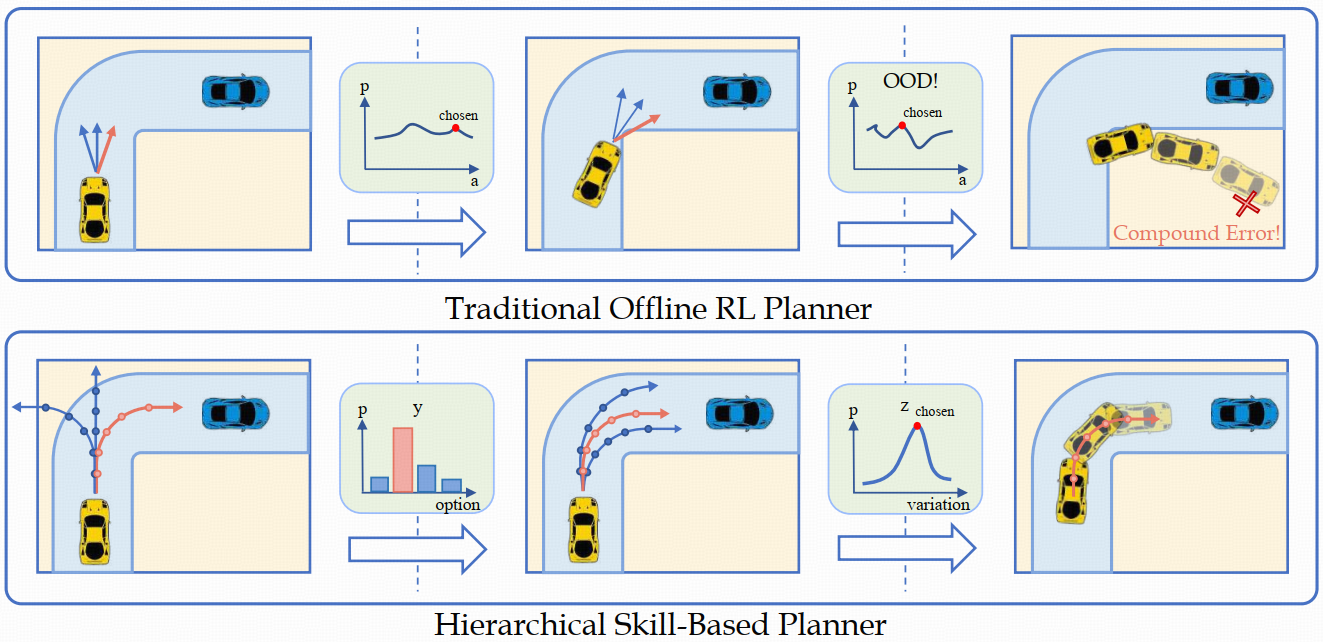
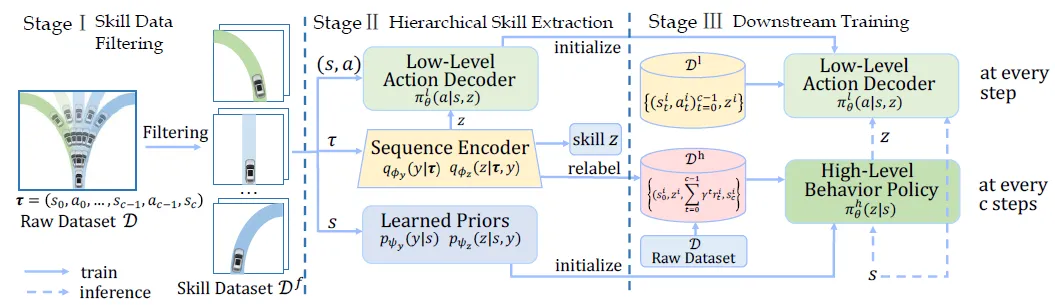
赵行团队在离线强化学习能够超越专家性能、无需危险环境交互的特性,提出了HsO-VP框架,实现了纯粹基于离线数据的长程运动规划。框架通过变分自编码器(VAE)从离线演示中学习技能,解决自动驾驶中的长期规划问题。设计了双分支序列编码器,有效应对后验坍塌问题。为自动驾驶车辆规划提供了一种新的强化学习方法。
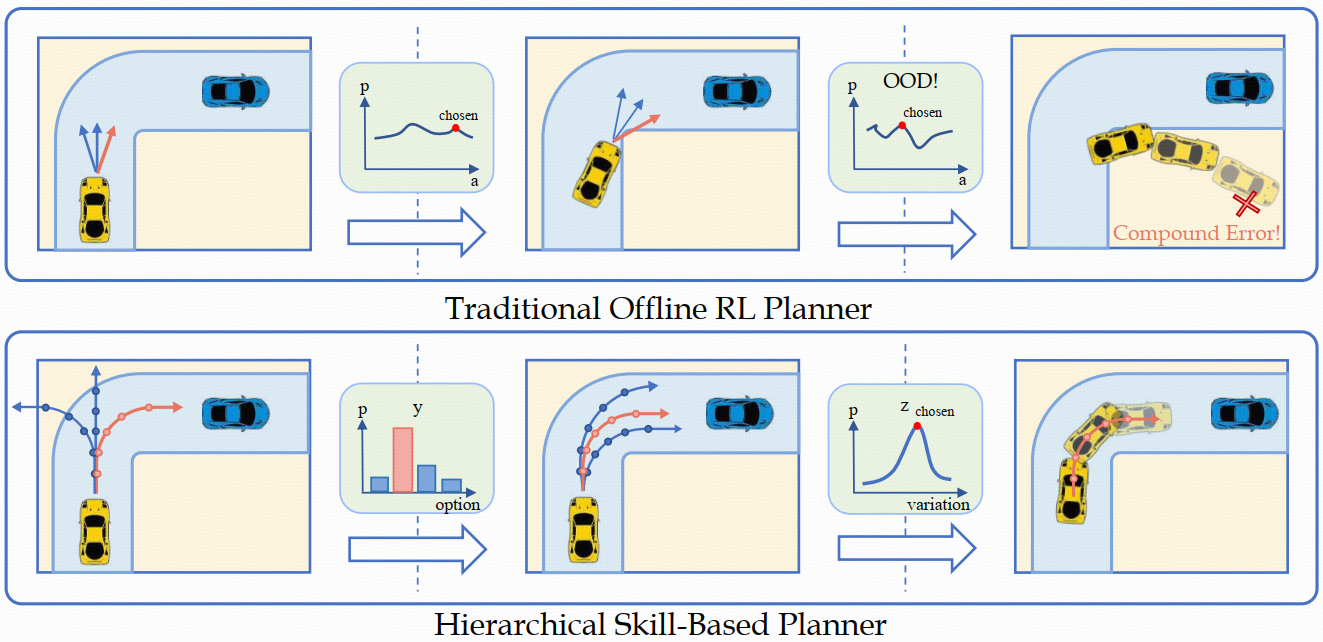
近来伴随着不同驾驶模拟器和大规模驾驶数据集的出现,基于深度学习的运动规划方式成为了自动驾驶的关键一环。区别于以往常用的模仿或强化学习算法,赵行团队瞄准了离线强化学习(Offline Reinforcement Learning, Offline RL)能够超越专家性能、无需危险环境交互的特性,提出了HsO-VP框架,实现了纯粹基于离线数据的长程运动规划。框架以驾驶技能为根基,将规划分为提取有效驾驶技能和基于技能的策略学习两阶段,通过更高层次的规划和反馈来稳定长程驾驶过程。为解决常见技能提取时的后验坍塌问题,HsO-VP结合人类驾驶先验,引入了双分支序列编码器,以同时捕捉复杂驾驶技能的离散选项和连续变化,使框架能从离线数据中提取出灵活且可解释的大量驾驶技能。相比于先前方案,HsO-VP在新的测试场景中取得了6.4%的驾驶得分提升。
论文题目:Boosting Offline Reinforcement Learning for Autonomous Driving with Hierarchical Latent Skills, Zenan Li*, Fan Nie*, Qiao Sun, Fang Da, Hang Zhao, ICRA 2024
论文链接:https://arxiv.org/abs/2309.13614
------------------------------------------------------------------------------------------------------------------------------
成果4:视觉为中心的自动驾驶技术(2023年度)
尽管自动驾驶技术在过去几年有着进展,但是高级别自动驾驶技术却一直难以落地。赵行团队指出了现有自动驾驶技术存在的泛化性问题,在于过分依赖激光雷达和高精度地图,并提出了以视觉为中心的自动驾驶框架。
在这个框架下,课题组发表了多篇代表性论文,改变了行业范式,包括首个视觉Transformer的三维物体检测模型DETR3D、跟踪模型MUTR3D、端到端运动预测模型ViP3D;用视觉神经先验网络实现在线的地图感知Neural Map Prior,代替了以往的手工地图标注方案;首个用于通用障碍物感知的三维占据网格数据集Occ3D等。
该系列算法成果在多个国际竞赛上拿到冠军,为行业多数头部企业所使用或借鉴。合作企业理想汽车公司在多次产品发布会上提到我们的科研成果带来的价值。至今,理想汽车公司已经将该系列成果部署于超过60万台电动汽车的辅助驾驶系统中,为国产辅助驾驶方案装机量第一,在国际上仅次于Mobileye和Tesla,实现了巨大的产业价值。


![]()
成果研究论文:
[1] Xuan Xiong, Yicheng Liu, Tianyuan Yuan, Yilun Wang, Yue Wang, Hang Zhao, Neural Map Prior for Autonomous Driving, CVPR 2023 查看PDF
[2] Xiaoyu Tian, Tao Jiang, Longfei Yun, Yucheng Mao, Huitong Yang, Yue Wang, Yilun Wang, Hang Zhao. Occ3D: A Large-Scale 3D Occupancy Prediction Benchmark for Autonomous Driving. NeurIPS 2023 Dataset Track. 查看PDF
------------------------------------------------------------------------------------------------------------------------------
成果3:机器人跑酷学习(2023年度)
近两年足式机器人的发展着重在复杂地形的移动能力,但是四足机器人的通过性始终没有超过传统的特种轮式机器人。赵行团队联合斯坦福大学,开发并开源了机器人跑酷学习(Robot Parkour Learning)项目,利用视觉和强化学习实现了四足机器人的高动态移动能力,包括:匍匐前进、跳上高台、跨越沟坎等。在这个项目中,我们从传统轨迹优化算法中寻找灵感,采用软动力学约束的方式成功让机器狗训练出特殊的步态以应对超过自身尺寸的障碍物,并且在微调阶段,让强化学习算法成功应用到了真实的机器狗上。Robot Parkour Learning项目得到的跑酷策略,还可以快速迁移到不同形态的机器狗上。Robot Parkour Learning的发表标志着四足机器人找到了它超过传统移动机器人的应用场景和机器学习算法实现。目前,Robot Parkour Learning项目已经开源了训练代码和强化学习模型,并成功在CoRL 2023会场实地展示和在同行的四足机器人上得到成功应用。Robot Parkour Learning项目在今年的机器人学习会议CoRL 2023上,入围了最佳系统论文奖(Best System Paper Award Finalist, Top3)。

研究领域:四足机器人的高动态移动
主要完成人:庄子文
项目网站:https://robot-parkour.github.io/
研究论文:Zhuang, Ziwen, Zipeng Fu, Jianren Wang, Christopher Atkeson, Sören Schwertfeger, Chelsea Finn, and Hang Zhao. ‘Robot Parkour Learning’. In Conference on Robot Learning (CoRL), 2023. 查看PDF
------------------------------------------------------------------------------------------------------------------------------
成果2:自动驾驶行为仿真(2022年度)
主流的自动驾驶方案依赖于大量的道路测试来衡量自动驾驶的水平,而把测试放入计算机仿真环境是未来规模化自动驾驶的重要路线。此外,仿真器还能被用于算法调试和训练数据生成。自动驾驶行为仿真器的构建面临了许多挑战,需要进行多智能体的意图和轨迹建模,同时需要考虑自车对环境和人的响应。赵行团队开发并且开源了首个基于机器学习的闭环自动驾驶行为仿真器InterSim。InterSim基于大规模真实数据集(Waymo Open Dataset)的车辆行为进行模型训练;在应用时,当轨迹规划器使用不同的策略时,仿真器能给出不同的、且逼真的行为反应。InterSim的发布是自动驾驶领域的重要里程碑,为自动驾驶规划算法提供了评测平台和训练数据。目前InterSim已经吸引了全世界几十个团队使用。
研究领域:自动驾驶
主要完成人:孙桥、赵行
项目网站:https://tsinghua-mars-lab.github.io/InterSim/
研究论文:Qiao Sun, Xin Huang, Brian C Williams, Hang Zhao, InterSim: Interactive Traffic Simulation via Explicit Relation Modeling, IROS 2022 查找PDF
------------------------------------------------------------------------------------------------------------------------------
成果1:从射频信号中恢复高质量(2022年度)
麦克风是人机交互和窃听领域中常见的设备,但在有干扰噪音和隔音材料的场景下,其性能会大幅下降。射频信号不受噪音和光照的影响并且可以穿过许多隔音以及不透明的障碍物。基于射频信号的这种性能,赵行团队提出了Radio2Speech,首个使用毫米波雷达信号来恢复高质量语音的系统。使用射频信号来恢复语音信号的原理是:声音产生于声源的震动,毫米波雷达向声源发射信号,通过对反射的雷达信号进行处理可以得到相应的震动信号,从而恢复原始的音频信号。Radio2Speech在安静环境下可以恢复与麦克风质量相当的语音,而在嘈杂环境和有隔音玻璃的环境下表现远优于传统的麦克风。
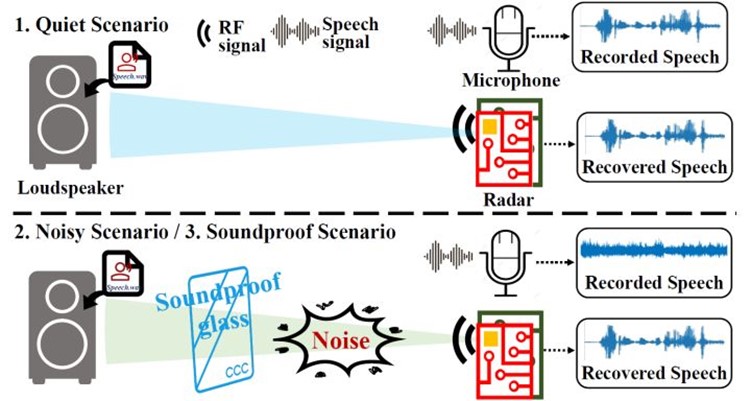
研究领域:多传感器学习
主要完成人:赵闰宁、于江涛、赵行
项目网站:https://zhaorunning.github.io/Radio2Speech/
研究论文:Running Zhao, Jiangtao Yu, Tingle Li, Hang Zhao*, Edith C.H. Ngai*, Radio2Speech: High Quality Speech Recovery from Radio Frequency Signals, Interspeech 2022 查看PDF



37. Embrace Contacts: Humanoid Shadowing with Full Body Ground Contacts, Ziwen Zhuang, Hang Zhao†,CoRL 2025.
36. Playful DoggyBot: Learning Agile and Precise Quadrupedal Locomotion, Xin Duan,Ziwen Zhuang,Hang Zhao†,Sören Schwertfeger†,IROS 2025.
35. MoE-Loco: Leveraging Mixture of Experts for Multi-Task Locomotion, Runhan Huang*, Shaoting Zhu*, Yilun Du, Hang Zhao†,IROS 2025.
34. GS-Occ3D: Scaling Vision-only Occupancy Reconstruction with Gaussian Splatting, Baijun Ye*, Minghui Qin*, Saining Zhang*, Moonjun Goon, Shaoting Zhu, Zebang Shen, Luan Zhang, Lu Zhang, Hao Zhao, Hang Zhao†,ICCV 2025.
33. LONG3R: Long Sequence Streaming 3D Reconstruction, Zhuoguang Chen* Minghui Qin*, Tianyuan Yuan*, Zhe Liu, Hang Zhao†,ICCV 2025.
32. Uncertainty-Aware Decision Transformer for Stochastic Driving Environments, Zenan Li, Fan Nie, Qiao Sun, Fang Da, and Hang Zhao†, https://arxiv.org/abs/2309.16397, CoRL 2024.
31. Humanoid Parkour Learning, Ziwen Zhuang, Shenzhe Yao, Hang Zhao†, https://openreview.net/forum?id=fs7ia3FqUM, CoRL 2024.
30. PreSight: Enhancing Autonomous Vehicle Perception with City-Scale NeRF Priors, Tianyuan Yuan, Yucheng Mao, Jiawei Yang, Yicheng Liu, Yue Wang, Hang Zhao†, https://arxiv.org/abs/2403.09079, ECCV 2024.
29. CVT-Occ: CVT-Occ: Cost Volume Temporal Fusion for 3D Occupancy Prediction, Zhangchen Ye*, Tao Jiang*, Chenfeng Xu, Yiming Li, Hang Zhao†, https://github.com/Tsinghua-MARS-Lab/CVT-Occ, ECCV 2024.
28. Zenan Li*, Fan Nie*, Qiao Sun, Fang Da, Hang Zhao, Boosting Offline Reinforcement Learning for Autonomous Driving with Hierarchical Latent Skills, ICRA 2024
27. Simian Luo, Chuanhao Yan, Chenxu Hu, Hang Zhao, Diff-Foley: Synchronized Video-to-Audio Synthesis with Latent Diffusion Models, Conference on Neural Information Processing Systems (NeurIPS), 2023 查看PDF
26. Ziwen Zhuang, Zipeng Fu, Jianren Wang, Christopher G Atkeson, Sören Schwertfeger, Chelsea Finn, Hang Zhao, Robot Parkour Learning, International Conference on Robots Learning (CORL), 2023 查看PDF
25. Liangtao Zheng, Yicheng Liu, Yue Wang, Hang Zhao, Cross-dataset Sensor Alignment: Making Visual 3D Object Detector Generalize, International Conference on Robots Learning (CORL), 2023 查看PDF
24. Tong Zhang, Yingdong Hu, Hanchen Cui, Hang Zhao, Yang Gao, A Universal Semantic-Geometric Representation for Robotic Manipulation, International Conference on Robots Learning (CORL), 2023 查看PDF
23. Qiao Sun, Xin Huang, Brian C. Williams, Hang Zhao, P4P: Conflict-Aware Motion Prediction for Planning in Autonomous Driving, International Conference on Intelligent Robots and Systems (IROS), 2023 查看PDF
22. Running Zhao, Jiangtao Yu, Hang Zhao, Edith C.H. Ngai, Radio2Text: Streaming Speech Recognition Using mmWave Radio Signals, Ubicomp/ISWC, 2023 查看PDF
21. Xiaoyu Tian*, Tao Jiang*, Longfei Yun, Yucheng Mao, Huitong Yang, Yue Wang, Yilun Wang, Hang Zhao, Occ3D: A Large-Scale 3D Occupancy Prediction Benchmark for Autonomous Driving, Conference on Neural Information Processing Systems (NeurIPS), 2023 查看PDF
20. Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, Hang Zhao, VectorMapNet: End-to-end Vectorized HD Map Learning, International Conference on Machine Learning (ICML), 2023查看PDF
19. Xuan Xiong, Yicheng Liu, Tianyuan Yuan, Yilun Wang, Yue Wang, Hang Zhao, Neural Map Prior for Autonomous Driving, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023查看PDF
18. Xuanyao Chen, Zhijian Liu, Haotian Tang, Li Yi, Hang Zhao, Song Han, SparseViT: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023查看PDF
17. Junru Gu, Chenxu Hu, Tianyuan Zhang, Xuanyao Chen, Yilun Wang, Yue Wang, Hang Zhao, ViP3D: End-to-end Visual Trajectory Prediction via 3D Agent Queries, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023查看PDF
16. Zitian Tang, Wenjie Ye, Wei-Chiu Ma, Hang Zhao, What Happened 3 Seconds Ago? Inferring the Past with Thermal Imaging, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 查看PDF
15. Renhao Wang, Jiayuan Mao, Joy Hsu, Hang Zhao, Jiajun Wu, Yang Gao, Programmatically Grounded, Compositionally Generalizable Robotic Manipulation, International Conference on Learning Representation(ICLR), 2023 查看PDF
14. Zihui Xue, Zhengqi Gao, Sucheng Ren, Hang Zhao, The Modality Focusing Hypothesis: Towards Understanding Crossmodal Knowledge Distillation, International Conference on Learning Representation(ICLR), 2023 查看PDF
13. Qiao Sun, Xin Huang, Brian C Williams, Hang Zhao,InterSim: Interactive Traffic Simulation via Explicit Relation Modeling, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022
查看PDF
12. Renhao Wang, Hang Zhao, Yang Gao, CYBORGS: Contrastively Bootstrapping Object Representations by Grounding in Segmentation, European Conference on Computer Vision (ECCV), 2022 查看PDF
11. Tingle Li, Yichen Liu, Andrew Owens, Hang Zhao, Learning Visual Styles from Audio-Visual Associations, European Conference on Computer Vision (ECCV), 2022 查看PDF
10. Running Zhao, Jiangtao Yu, Tingle Li, Hang Zhao, Edith C.H. Ngai, Radio2Speech: High Quality Speech Recovery from Radio Frequency Signals, Interspeech 2022 查看PDF
9. Zui Chen, Yansen Jing, Shengcheng Yuan, Yifei Xu, Jian Wu, Hang Zhao, Sound2Synth: Interpreting Sound via FM Synthesizer Parameters Estimation, International Joint Conference on Artificial Intelligence(IJCAI), 2022 查看PDF
8. Sucheng Ren, Zhengqi Gao, Tianyu Hua, Zihui Xue, Yonglong Tian, Shengfeng He, Hang Zhao, Co-advise: Cross Inductive Bias Distillation, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 查看PDF
7. Jianren Wang, Ziwen Zhuang, Hang Zhao, SEMI: Self-supervised Exploration via Multisensory Incongruity, IEEE International Conference on Robotics and Automation(ICRA), 2022 查看PDF
6. Yu Huang, Chenzhuang Du, Zihui Xue, Xuanyao Chen, Hang Zhao, Longbo Huang, What Makes Multi-Modal Learning Better than Single (Provably), Conference and Workshop on Neural Information Processing Systems(NeuRIPS), 2021 查看PDF
5. Chenxu Hu, Qiao Tian, Tingle Li, Yuping Wang, Yuxuan Wang, Hang Zhao, Neural Dubber: Dubbing for Videos According to Scripts, Conference and Workshop on Neural Information Processing Systems(NeuRIPS), 2021 查看PDF
4. Tingle Li, Yichen Liu, Chenxu Hu, Hang Zhao, CVC: Contrastive Learning for Non-parallel Voice Conversion, Interspeech 2021 查看PDF
3. Zihui Xue, Sucheng Ren, Zhengqi Gao, Hang Zhao, Multimodal Knowledge Expansion, IEEE International Conference on Computer Vision(ICCV), 2021 查看PDF
2. Tianyu Hua, Wenxiao Wang, Zihui Xue, Yue Wang,Sucheng Ren, Hang Zhao, On Feature Decorrelation in Self-Supervised Learning, IEEE International Conference on Computer Vision(ICCV), 2021 查看PDF
1. Jianren Wang, Yujie Lu, Hang Zhao, CLOUD: Contrastive Learning of Unsupervised Dynamics, Conference on Robot Learning(CoRL), 2020 查看PDF