
2025-05-30

Innovation Highlights
张景昭—提出在parity-learning的问题框架下,即使在表达能力充足时,思维链仍能显著提高样本效率。具体而言,当使用 CoT 时,Transformer 能以多项式级别的样本量学会目标函数;而在不使用 CoT 时,所需的样本数量则是指数级的;CoT 通过在输入 token 之间引入稀疏的序列依赖关系,简化了学习过程,并使注意力机制呈现稀疏且可解释的特征。
Achievements Summary
从依赖关系的稀疏性到注意力模式的稀疏性:揭示思维链如何提高Transformer的样本效率
思维链(CoT)能显著提升大语言模型(LLM)的推理能力。当前的理论研究通常将这一提升归因于模型的表达能力和计算能力的增强。然而,即使在简单任务上,大模型仍可能出现失误,因此团队认为,在大模型的语境下,表达能力并非主要的限制因素。
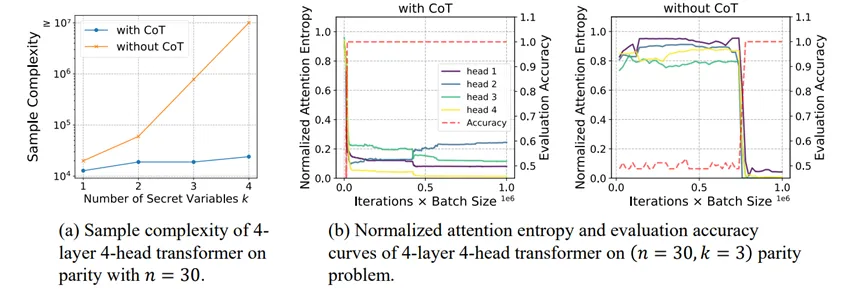
图. (1)使用CoT可以显著提高样本效率。(b)当注意力层变得更加稀疏,准确率都会出现显著提升。
思维链(CoT)通过将复杂任务分解为简单、可操作的子步骤,显著提升了模型的推理能力。显著提升了模型的推理能力。为了深入探究思维链成功背后的机制,张景昭课题组以sparse parity这一简单问题为切入点,证明了思维链能够以指数级降低Transformer模型的样本复杂度。
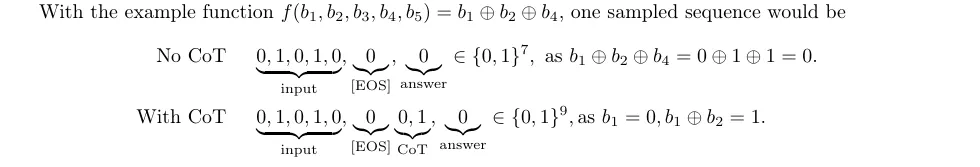
图. 在无/有CoT时的问题和数据格式
具体来说,项目组成员从理论上证明了:
(1)表达能力充足:即使在没有思维链的情况下,仅需一层、单头的Transformer模型即可表达sparse parity问题。
(2)无思维链时的困难性:在没有思维链时,Transformer模型需要指数多的样本复杂度,才能得到非平凡的准确率。
(3)思维链能降低模型的样本复杂度:当使用带有思维链的数据进行训练时,Transformer模型只需要接近线性的样本复杂度,即可在sparse parity问题上达到完美的准确率。
此外,由于思维链分解了token之间的依赖关系,Transformer的注意力层在该问题上呈现稀疏且可解释的特征。
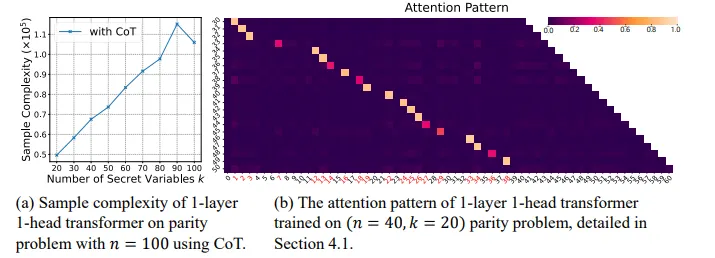
图. (a)对于固定的n,使用思维链学习sparse parity问题的样本复杂度大致随k线性增长。(b)使用思维链时,Transformer学到的注意力模式具有可解释性。
这一简化模型的结论在真实场景中得到了验证:与无CoT的数据相比,预训练模型在有CoT数据上展现出更稀疏的注意力模式;而通过CoT数据微调,可以进一步增强注意力的稀疏性。
本工作通过对简化模型的理论分析,从理论上证明了思维链能够显著降低Transformer模型的样本复杂度,对进一步理解推理模型的训练原理具有重要意义。本论文共同一作为上海期智研究院实习生温凯越,上海期智研究院实习生、清华大学本科生张华清,通讯作者为上海期智研究院PI、清华大学助理教授张景昭。
论文信息:
From Sparse Dependence to Sparse Attention: Unveiling How Chain-of-Thought Enhances Transformer Sample Efficiency, Kaiyue Wen*, Huaqing Zhang*, Hongzhou Lin, Jingzhao Zhang†, https://arxiv.org/abs/2410.05459, ICLR 2025.







