
2025-05-30

Innovation Highlights
高阳—提出一项关于机械臂操作中数据扩展定律(Data Scaling Laws)的研究。该研究旨在探明数据扩展能否提升机器人策略的零样本泛化能力,使其适应新物体和新环境。团队通过大规模实证研究,利用通用操作接口 (UMI) 收集了超过40,000个演示,并在超过15,000次真实机器人实验中验证了策略表现。
Achievements Summary
机器人操作模仿学习的数据扩展定律
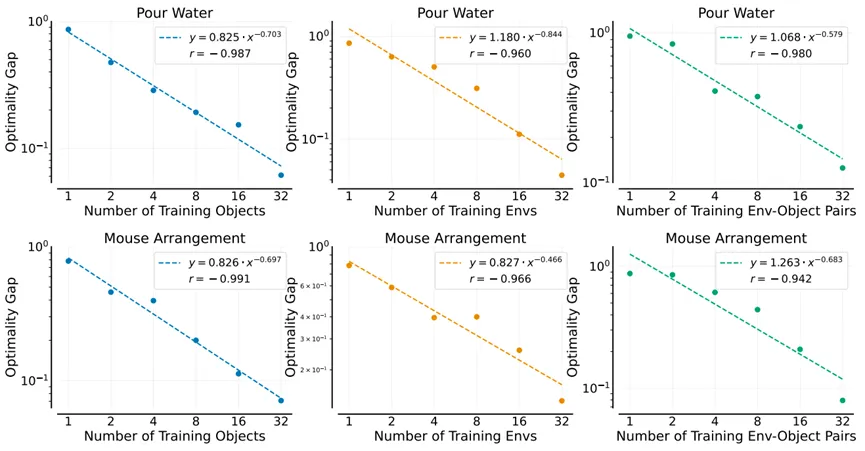
图1. 幂律关系
数据扩展已在自然语言处理和计算机视觉等领域引发深刻变革,赋予模型出色的泛化能力。文章旨在探究机器人领域,特别是机器人物体抓取任务中是否存在类似的数据扩展定律,以及通过恰当的数据扩展,单任务机器人策略是否能在面对同一类别中的任意对象和任意环境时实现零样本部署。现有的机器人策略大多缺乏这种零样本泛化能力。

图2. 真机实验任务
为了回答上述问题,研究团队对模仿学习中的数据扩展进行了全面的实证研究。通过在大量环境和不同对象中收集数据,研究团队系统地研究了单任务策略在面对新环境或新对象时,其性能如何随训练环境或物体数量的增加而变化。研究团队还考察了在环境和物体数量固定的情况下,演示数量对策略泛化能力的影响。研究团队使用手持式抓手 (UMI) 在各种环境和不同对象上收集人类演示数据,并使用 Diffusion Policy 对数据进行建模。研究团队首先聚焦于“倒水”和“整理鼠标”这两个任务进行案例研究,深入分析了策略泛化能力随环境、对象和演示数量的变化,并总结了数据扩展定律。研究发现,如代表图中所示,策略对新对象、新环境或两者的泛化能力与训练对象、训练环境或训练环境-对象对的数量大致呈幂律关系。相比之下,当环境和物体数量固定时,演示数量与策略泛化性能之间没有明显的幂律关系。性能最初随演示数量增加而快速提升,但随后会趋于平稳。

图3.数据展示
研究团队的研究收集了超过40,000个演示,并在严格的评估协议下执行了超过15,000次真实世界机器人操作。实验结果揭示了多项有趣的发现:策略对环境和对象的多样性依赖远大于绝对的演示数量。一旦每个环境或对象的演示数量达到某个阈值,增加更多演示的效果微乎其微。基于这些洞察,研究团队提出了一种高效的数据收集策略。研究团队将该策略应用于“折叠毛巾”和“拔充电器”这两个新任务。通过四名数据收集者一个下午的工作,研究团队收集了充足的数据,使得这四个任务的策略在包含未见物体的全新环境中实现了约90%的成功率。这凸显了研究团队数据收集策略的高效性,并表明训练一个能够在新环境和对象中实现零样本部署的单任务策略所需的时间和成本是适度的。研究团队还初步探索模型尺寸扩展,发现视觉编码器的尺寸扩展可以显著提升性能。
这项工作为提高机器人操作的样本效率提供了新思路,并突显了数据多样性在机器人任务泛化中的前景。相关成果被ICLR 2025评选为Oral,并被CoRL X-Embodiment Workshop评选为Best Paper。本论文共同一作为上海期智研究院实习生、清华大学博士生林凡淇和胡英东,通讯作者为高阳助理教授。共同作者为清华大学本科生盛平岳,上海期智研究院实习生、清华大学博士生汶川,清华大学博士生游嘉诚。
论文信息:
Data Scaling Laws in Imitation Learning for Robotic Manipulation, Fanqi Lin*, Yingdong Hu*, Pingyue Sheng, Chuan Wen, Jiacheng You, Yang Gao†, https://data-scaling-laws.github.io/,ICLR 2025.







