
2025-10-31

Innovation Highlights
许华哲团队联合上海交通大学卢策吾团队提出了一种慢-快(slow-fast)层次化视觉触觉模仿学习算法RDP,将动作预测分为“低频隐空间扩散”(复杂全局规划)与“高频触觉微调”(闭环力控调节)两级,解决了传统 IL 方法在执行动作块期间“无法即时调整”与“动作连贯性与实时响应性难以兼得”的矛盾,在三项具有挑战性的接触丰富任务(剥皮、擦拭、双臂提杯)上相较于现有视觉 IL 基线在任务完成度、受扰动鲁棒性等方面提升显著。
Achievements Summary
RDP:面向接触丰富操作的慢-快视触觉融合策略学习Best Paper Finalist
TacAR基于 Meta Quest3 AR 显示,将触觉传感器的 3D 变形场渲染叠加在机器人末端执行器上;支持 GelSight Mini、MCTac 与关节力矩传感器,硬件成本约 $500,兼具跨传感器、跨机型(单臂/双臂)部署能力。

图1. TactAR 远程操作系统概述
RDP由快慢策略构成,Slow Policy(慢策略):使用基于隐空间扩散模型的动作块预测,低频 (1–2 Hz) 运行,负责复杂轨迹与非马尔可夫行为建模;Fast Policy(快策略):采用不对称编码器(Asymmetric Tokenizer)+ GRU 解码,以 ≥ 20 Hz 频率对隐空间动作在执行过程中进行闭环微调,精准控制接触力并快速响应扰动。
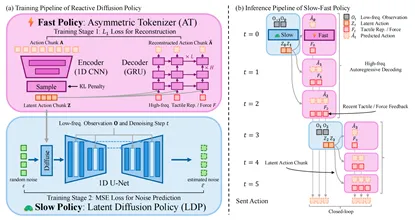
图2. 反应扩散策略(RDP)框架概述
团队在3项高难度接触丰富任务上进行评测:(1)剥皮任务:机器人需在不同环境扰动下,对悬空黄瓜进行毫米级精度剥皮;(2)擦拭任务:机器人需在曲面花瓶上进行擦拭,实时调整切线方向与接触力;(3)双臂提杯任务:双机械臂需在不挤压纸杯的前提下完成抓取与升杯,具备双臂协同与力控要求。实验结果显示,RDP 在所有任务中相较于 Diffusion Policy 基线平均提升 35%。

图3. 三项实验任务:剥离、擦拭与双手协同举升
团队在 GelSight Mini、MCTac 与关节力矩传感器上进行跨传感器评估,验证了 RDP 在不同传感模式下的泛化能力;同时还通过用户研究表明,TactAR 触觉 AR 显著提高示教过程稳定性——剥皮任务中示教数据接触力抖动减少 > 50%,数据质量提升直接带来 RDP 性能提升 > 30%(未用触觉 → 带触觉 0.33 → 0.90)
相关成果入选2025 RSS Best Paper Finalist。本论文共同第一作者包括上海交通大学博士生薛寒、任杰骥、陈文迪;共同通讯作者为研究院PI、清华大学助理教授许华哲,上海交通大学教授卢策吾。其他作者包括研究院实习生、清华大学博士生张谷,上海交通大学谷国迎教授等。
论文信息: Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation, Han Xue*, Jieji Ren*, Wendi Chen*,Gu Zhang, Yuan Fang, Guoying Gu, Huazhe Xu†, Cewu Lu†, https://reactive-diffusion-policy.github.io/, RSS 2025.







