
2025-10-31

Innovation Highlights
赵行团队提出了一种全新鲁棒四足机器人运动控制方法—Robust Robot Walker,使机器人能够仅依赖本体感知在复杂真实环境中跨越微型障碍。团队设计了一种两阶段强化学习训练框架,联合了接触力编码器与陷阱分类器,辅助策略网络学习对微型陷阱的内隐感知与反应机制。团队还构建了首个微型陷阱基准测试集,涵盖三类障碍场景。在大规模仿真和真实机器人部署实验中,团队提出方法在通过率、路径稳定性、任务完成时间等多个指标上显著优于现有SOTA方法,展现出卓越的鲁棒性与实用性。
Achievements Summary
(STR2)鲁棒行走的机器人:学习灵巧跨越微型陷阱技能
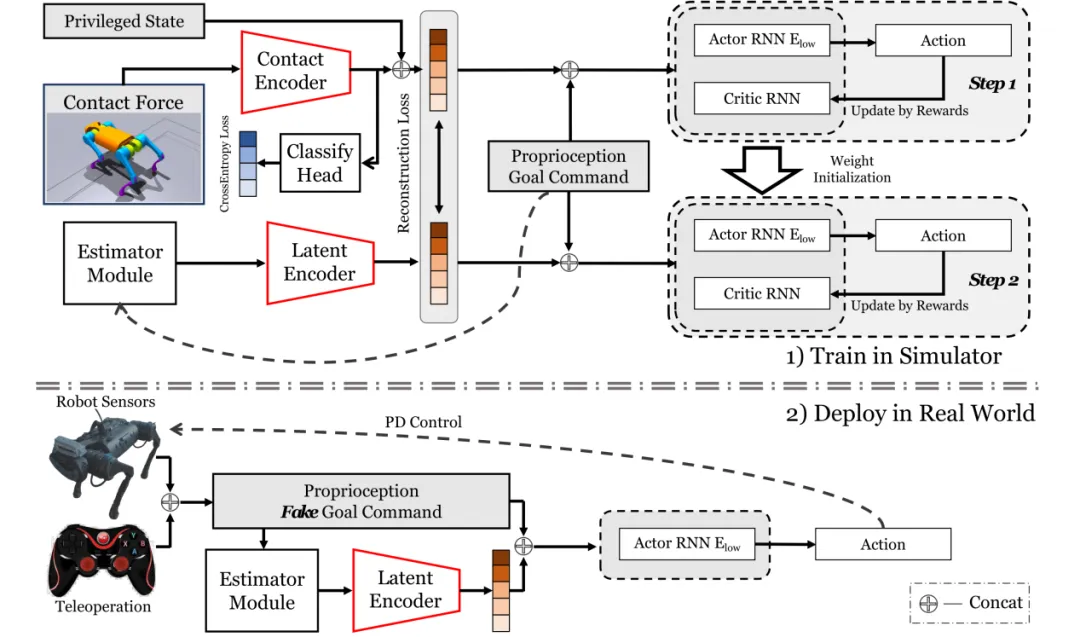
图. (上) Robust Robot Walker在仿真中的两步训练框架
(下) 训练所得策略模型在真实机器人中的部署
赵行团队提出了一套围绕接触力建模与本体控制融合的强化学习算法,突破了传统依赖外部感知的四足机器人越障范式。在算法设计上,团队构建了一个两阶段训练架构,在初期引入特权状态与接触力进行策略初始化,后期转向纯本体感知控制。该架构利用本体感知估计和预测特权状态和接触力,形成了显式+隐式状态估计的融合机制,显著提升了机器人识别和应对复杂接触场景的能力。此种编码策略不仅提升了策略泛化性,还有效缓解了仿真到现实的迁移问题,尤其是在存在摩擦、阻尼等外部环境偏差的情况下依然能保持稳定运行。
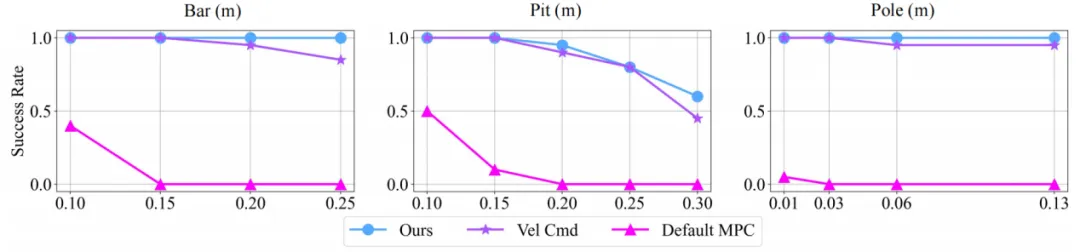
图. 真机实验成功率曲线
在理论建模方面,团队对本体信息驱动下的目标追踪任务进行了结构性重构。团队将传统的速度指令控制转换为“伪目标指令”驱动的目标位置追踪,从而实现在无定位系统条件下的近似全向控制。同时,围绕该任务重新设计了多个密集型奖励函数,如朝向奖励、目标接近度、静止奖励等,不仅优化了策略收敛性,也自然地训练出了多样化运动策略。团队提出的训练方法使机器人在面对不同障碍组合时能够自主调整步态与策略,展现出极高的适应性。
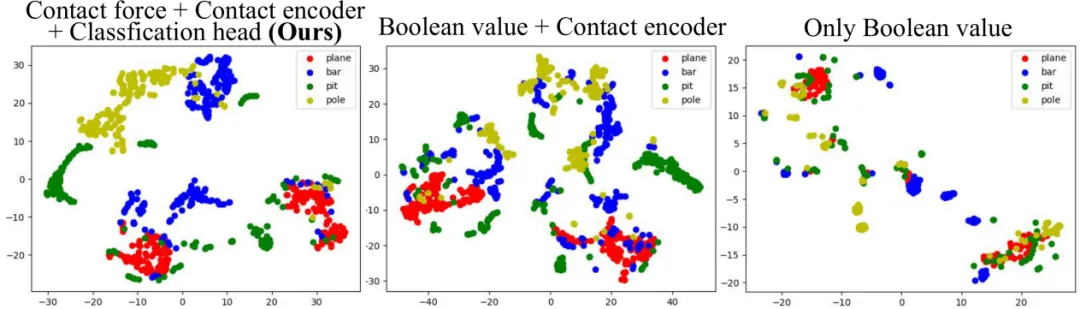
图.隐空间T-分布领域嵌入(t-sne)分布图
团队主要解决了两个长期存在的挑战:一是外部感知在实际场景中对细微障碍物识别不准的问题;二是控制策略在无精确状态估计条件下无法稳定部署的问题。通过引入基于接触力的隐状态估计器与融合表示空间,机器人不再依赖色彩图像或深度图像即可“感知”地形类型,并自动调整运动行为。此外,训练策略具备良好的可迁移性,能够在不同障碍密度、障碍组合顺序甚至完全未见过的障碍构型下稳定运行。
该工作的最大价值在于其面向真实部署的通用性与实用性。在不依赖任何视觉、定位、运动捕捉系统的前提下,该策略实现了在真实世界中快速部署、零样本推理与可控移动。相比传统方法,所需传感器更少、部署成本更低,具有显著的工程可落地优势。此外,该工作也首次系统性地定义与建立了“微型陷阱”任务与评测标准(Tiny Trap Benchmark),填补了四足机器人越障领域在“细节级障碍”层面的研究空白。

图9. “微型陷阱”任务与评测标准。四足机器人从跑道左侧出发,跨越多种障碍物最终到达右侧的目标点
Robust Robot Walker为未来面向复杂、感知受限、未知地形环境下的高性能移动机器人提供了全新范式,也为多感知融合、低感知控制、灵巧越障等方向的研究提供了坚实基础。本论文一作为上海期智研究院实习生、清华大学博士生朱少廷,通讯作者为上海期智研究院PI、清华大学助理教授赵行。共同作者为上海期智研究院实习生、清华大学本科生黄润晗和上海期智研究院实习生牟林湛。
论文信息:
Robust Robot Walker: Learning Agile Locomotion over Tiny Traps, Shaoting Zhu, Runhan Huang, Linzhan Mou, Hang Zhao†, https://robust-robot-walker.github.io/, ICRA 2025.







