
2025-10-31

Innovation Highlights
弋力团队提出了“掩码自回归预训练算法”(MAP)来激发混合Mamba-Transformer视觉架构的潜力。通过分别深入分析Mamba和Transformer视觉骨干预训练的关键因素,设计了适用于混合Mamba-Transformer的统一预训练策略。这一策略在2D和3D任务上均得到充分验证,为混合Mamba-Transformer视觉架构的广泛应用和未来发展奠定了基础。
Achievements Summary
MAP:利用掩码自回归预训练释放混合Mamba-Transformer视觉骨干网络的潜力
本研究提出了一种名为MAP (Masked Autoregressive Pretraining) 的创新预训练策略,旨在充分释放混合Mamba-Transformer视觉骨干网络的潜力。MAP策略巧妙地结合了两种主流的预训练方法—掩码自编码器 (Masked Autoencoders, MAE)和自回归 (Autoregressive, AR) 预训练。
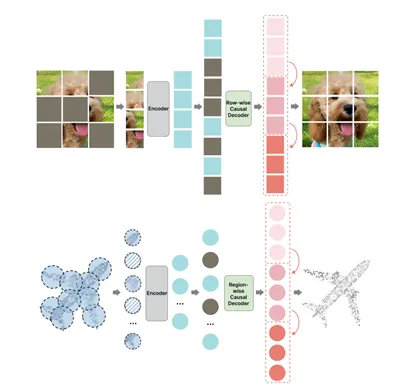
图. MAP: 掩码自回归预训练策略
论文核心关注了以下核心问题。 混合网络预训练难题:当前的预训练方法主要针对单一类型的网络架构(如仅Transformer或仅Mamba。如何有效地预训练结合了Mamba和Transformer的混合网络,以充分发挥各自优势,是一个尚未解决的关键挑战。MAP直接解决了这一痛点。 Mamba和Transformer模块的协同优化:在混合网络中,如何确保Mamba和Transformer组件都能得到充分且平衡的预训练,从而避免某个组件性能受限,是另一个难题。MAP通过其独特的结合方式,实现了对这两个模块的协同优化。
论文通过结合MAE和AR的优点,MAP使得预训练模型能够更好地学习到数据的局部和全局依赖关系,从而提升了模型的泛化能力和对不同视觉任务的鲁棒性。具体来说,论文引入了一种统一的范式,使得在预训练过程中能够同时优化Mamba和Transformer模块。具体的机制是,MAP在输入数据上执行掩码操作,然后利用自回归的方式预测被掩码的部分,同时通过重建损失来学习有效的表示。这种结合确保了对两种不同架构组件的有效学习。论文的核心在于认识到,单一的预训练策略(如MAE或AR)在处理混合架构时存在局限性,因为它们通常侧重于某种特定架构的优势。MAP的提出,是基于对Mamba在长上下文建模和计算效率方面的优势,以及Transformer在全局依赖捕获和可扩展性方面的优势的深入理解。MAP理论上通过互补的预训练任务,使得混合网络能够同时继承并增强这两种架构的优点。
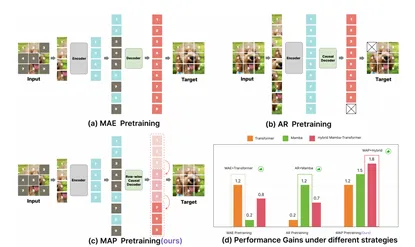
图. MAP, MAE和AR预训练的策略和性能对比
实验结果表明,经过MAP预训练的混合Mamba-Transformer视觉骨干网络在各种2D和3D数据集上显著超越了其他预训练策略,并达到了最先进的性能(state-of-the-art)。这证明了MAP在推动视觉骨干网络发展方面的巨大潜力。
MAP为混合网络的预训练提供了一个高效且通用的范式,这将加速此类创新架构在计算机视觉领域的应用和发展。它为设计和训练更强大、更高效的下一代视觉模型奠定了基础。本论文一作为上海期智研究院实习生、清华大学博士生刘昀泽,通讯作者为上海期智研究院PI、清华大学助理教授弋力。
论文信息:
MAP: Unleashing Hybrid Mamba-Transformer Vision Backbone’s Potential with Masked Autoregressive Pretraining, YunzeLiu, Li Yi†, https://github.com/yunzeliu/MAP, CVPR 2025.







