上海期智研究院PI,清华大学人工智能学院助理教授。
他于清华大学计算机系获得学士和博士学位,随后在新加坡国立大学计算机学院担任博士后研究员,现任清华大学人工智能学院助理教授。他的研究方向是高效多模态大模型。他主导了MiniCPM-V和MiniCPM-o系列模型的研发,系列模型累计下载量1600万次。他本科和博士毕业于清华大学,之后在新加坡国立大学从事博士后研究。其研究成果曾入选ICLR Spotlight、ECCV Oral以及Nature Communications亮点推荐。他曾获吴文俊人工智能科学技术奖优秀博士学位论文奖、英特尔中国学术成就奖、世界人工智能大会云帆奖等荣誉。
高效多模态大模型与深度视觉语言理解
成果2: GUICourse:从通用视觉语言模型迈向多功能图形界面智能体(2025年度)
姚远团队近期提出 GUICourse 框架,旨在将通用视觉语言模型(VLM)转化为可执行图形用户界面(GUI)操作的多功能智能体(Agent)。针对现有视觉语言模型在基础能力(OCR文字识别与视觉定位)和GUI知识(控件功能与交互逻辑)上的缺陷,团队提出三个核心课程学习数据集:(1)GUIEnv:增强模型对界面元素的OCR识别与视觉定位能力;(2)GUIAct:注入GUI控件功能知识;(3)GUIChat:强化人机交互指令理解能力。实验表明,经GUICourse训练的代理在单步/多步GUI任务中显著优于基线模型,仅3.1B参数的小规模代理即可高效完成复杂界面操作,为构建实用化视觉GUI代理提供了数据驱动的解决方案。本论文共同一作为人民大学博士生陈文通、清华大学科研助理崔竣博、清华大学博士生胡锦毅。通讯作者为研究院PI姚远。

图. 多个GUI任务示例
论文信息:
https://aclanthology.org/2025.acl-long.1065.pdf
GUICourse: From General Vision Language Models to Versatile GUI Agents. Wentong Chen1*, Junbo Cui*, Jinyi Hu*, Yujia Qin, Junjie Fang,Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo,Yuan Yao†, Yankai Lin1†, Zhiyuan Liu, Maosong Sun, ACL 2025
成果1: RLAIF-V: 基于开源AI反馈实现超过GPT-4V可信度(2025年度)
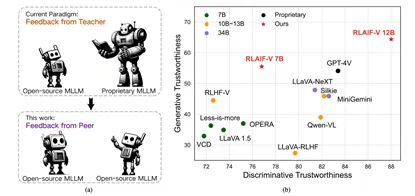
图.(左)RLAIF-V代表的从蒸馏模仿商用模型到高效学习同级别开源模型反馈的新偏好学习范式,(右)在生成和判别任务中的可信度评估结果
多模态大模型的最新成果代表了人工智能发展的一个重要里程碑,这些模型展现出了丰富的世界知识和多样的任务解决能力。然而,学术界和工业界都普遍发现多模态大模型容易生成与图像内容无关的反事实内容,影响了多模态大模型的可信度与可用性。为了解决这一问题,传统方法依赖劳动密集型的人工标注或蒸馏昂贵的闭源模型以获得偏好学习数据。这导致开源社区缺乏关于如何利用开源多模态大模型,构建高质量偏好数据的基础性知识。姚远团队提出的RLAIF-V,作为一种能够在完全开源范式下对多模态大模型进行偏好数据构造和学习的高效框架,从训练阶段和推理阶段两个方面最大化地利用了开源多模态大模型的能力。在6个基准测试上进行的自动化和人工评测实验结果表明,RLAIF-V在训练和推理阶段都大幅提升了模型的可信度。
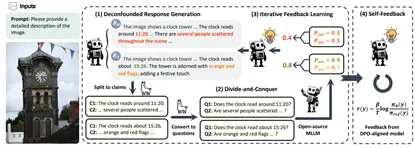
图. RLAIF-V数据构造及模型训练框架. HiRT通过层次化变压器模型来解决大模型推理慢的问题
姚远团队进一步分析RLAIF-V框架生成的偏好学习数据的泛化性,并验证发现用单个开源多模态大模型构造的偏好数据可以在众多常见多模态大模型上实现显著的可信度提升。
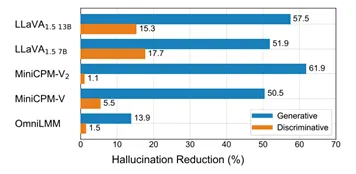
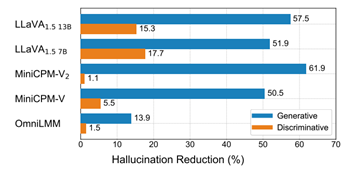
图. RLAIF-V 12B偏好数据显著提升其他多模态大模型可信度
RLAIF-V为可信多模态大模型构建提供了全新的思路,揭示了多模态大模型自学习提升可信度这一范式的可行性。
论文信息:
RLAIF-V: Open-Source AI Feedback Leads to Super GPT-4V Trustworthiness, Tianyu Yu, Haoye Zhang, Qiming Li, Qixin Xu, Yuan Yao, Da Chen, Xiaoman Lu, Ganqu Cui, Yunkai Dang, Taiwen He, Xiaocheng Feng, Jun Song, Bo Zheng, Zhiyuan Liu, Tat-Seng Chua, Maosong Sun, https://github.com/RLHF-V/RLAIF-V, CVPR 2025.





1. RLAIF-V: Open-Source AI Feedback Leads to Super GPT-4V Trustworthiness, Tianyu Yu, Haoye Zhang, Qiming Li, Qixin Xu, Yuan Yao, Da Chen, Xiaoman Lu, Ganqu Cui, Yunkai Dang, Taiwen He, Xiaocheng Feng, Jun Song, Bo Zheng, Zhiyuan Liu, Tat-Seng Chua, Maosong Sun, https://github.com/RLHF-V/RLAIF-V, CVPR 2025.
2. GUICourse: From General Vision Language Models to Versatile GUI Agents. Wentong Chen1*, Junbo Cui*, Jinyi Hu*, Yujia Qin, Junjie Fang,Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo,Yuan Yao†, Yankai Lin1†, Zhiyuan Liu, Maosong Sun, ACL 2025.