
袁洋
深度学习技术的蓬勃发展给众多领域带来了革命性的进步,在很多任务中深度学习模型的表现甚至超过了人类,尤其是在图像、自然语言处理等领域。然而,大多数这些精确的决策系统仍然是复杂的黑匣子,这意味着它们的内部逻辑和工作原理对用户来说是隐藏的,甚至专家也无法完全理解其做出判断的原因。这给深度学习模型应用在对人类健康、社会生产关系产生深远影响的领域(例如医疗、教育、法律、交通)带来了巨大挑战,因为可以被解释的深度学习模型才能让用户放心地采纳算法提供的建议。本课题组致力于探索前沿可解释性算法研究,做到在深度学习中不仅知其然,更要知其所以然。并计划将研究成果在医疗场景中部署,开发更加可信的深度学习辅助诊断系统。
在过去的几年里,研究界已经认识到可解释性问题的重要性,并致力于开发可解释模型和解释方法。现有的主流可解释性算法通常借助模型对输入数据的导数、数据集的改造、抽象特征的相关性、神经网络的注意力机制等多个角度研究,并且获得了一定进展。然而,这些方法的出现表明,在如何评估解释质量方面没有达成共识。
我们的研究方向是前沿可解释性算法,包含以下几个研究方向。
1. 一整套安全的,可解释的人工智能理论体系。对于计算机视觉,自然语言处理,机器学习等各个领域的基础模型给出统一普适的安全可解释模型增强,使人工智能系统拥有数学严格证明的安全性保障。在理论体系的保障下,从可解释性与鲁棒性的关系入手,为模型提供基于高质量知识图谱的、可交互的、多层级的可解释性。
2. 复合的可解释性。可解释性使用的元素可能有多重来源,使用的信息也可能来自输入空间、不同抽象程度的特征空间,将这些元素融合到一起的可解释性非常重要。
3. 可以被用户理解的可解释性。大部分深度学习模型的用户并不是深度学习专家,这些用户需要的是能够被理解的解释,而不是现有算法通常展示的特征重要性。
4. 具有交互功能的可解释性。在实际应用中,用户往往不仅仅满足于单一的答案与相应的解释,可能需要与模型交互获取多种类型的信息。因此为交互过程提供动态的可解释性是非常重要的。

目前,我们与中山医院糖尿病慢病管理课题组开展深入合作,计划分三个阶段实现深度学习辅助的胰岛素注射剂量推荐系统。
1. 首先,我们开发了专门为中山医院糖尿病人数据开发的深度学习模型。模型的输入数据包含了病人的检查信息与时序信息,我们通过糅合这两种不同性质的数据构建模型。目前我们的模型相较中山医院已有的机器学习模型效果有所提升,尤其降低了极端值的错误率。
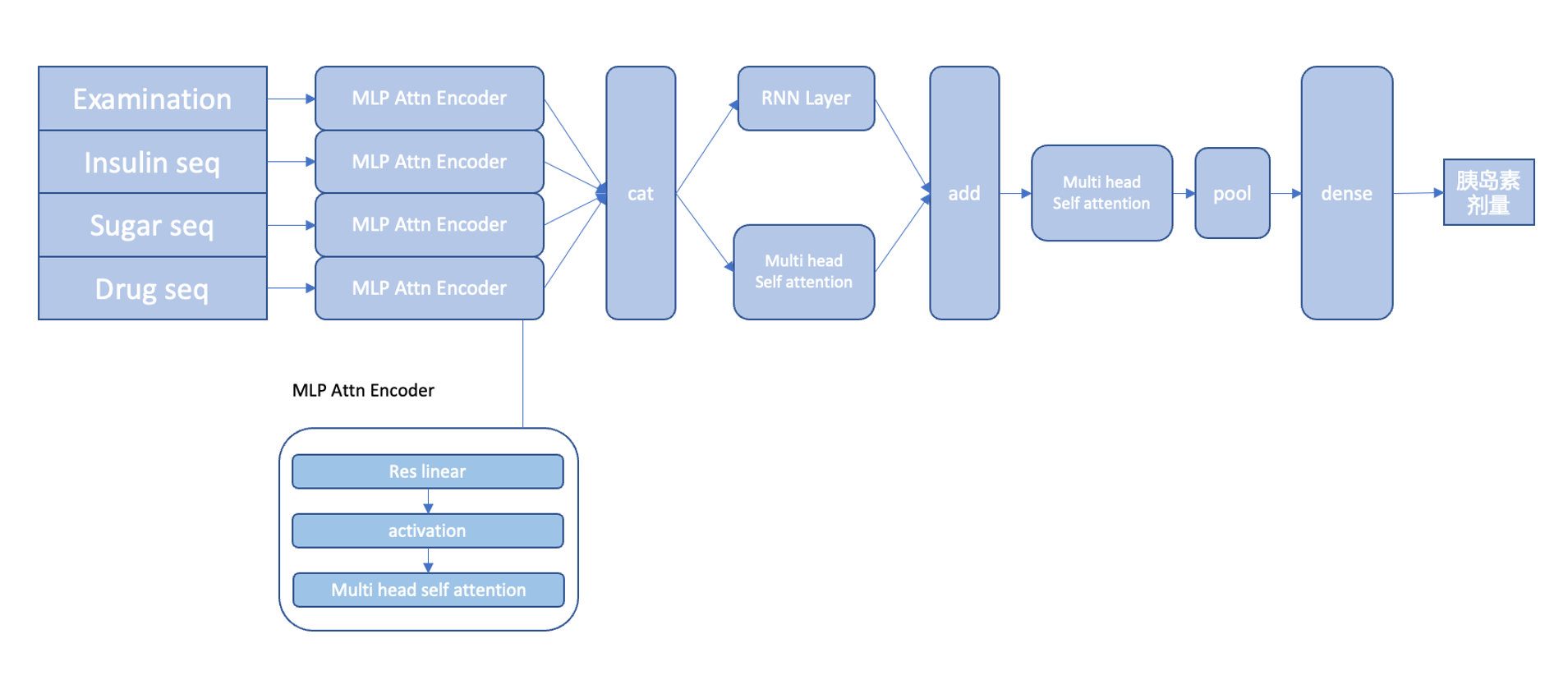
2. 其次,我们通过与医生沟通,建立符合医学原理的可解释性模型,并将模型解释内容转换成医生可以看懂的自然语言,以此供医生判断胰岛素推荐剂量是否合理,同时让病人做到自知。
3. 最后,我们计划在中山医院实际部署我们整套辅助诊断,提升诊断效率。













