
高阳
我们旨在探索新的计算机视觉、机器学习和强化学习算法来提高自动驾驶系统的性能。当前的工业自动驾驶系统大多数是基于手写规则式的。这些系统虽然在短期内可以取得良好的效果,但是长期来讲系统中会存在规则式系统难以处理的边界情况。因此,我们研究一种完全无人工书写规则的、纯机器学习的自动驾驶系统,即端到端自动驾驶系统。这种类型系统有潜力解决规则式系统难以解决的边界情况。
具体来讲,我们主要在以下三个方向进行研究。(1)端到端自动驾驶系统中的鲁棒性。即如何能够让机器学习模型的行为遵守因果规则,从而在面对新场景更加鲁棒。(2)探索自动驾驶的高数据效率强化学习解法。自动驾驶具有长尾失败情况难以处理的情况,为了能够自动纠正自动驾驶现实中错误的行为,我们将高数据效率强化学习算法应用于自动驾驶应用。(3)自监督视觉感知。为了在使用更少标签下,进一步提升自动驾驶模型的视觉能力,我们从自监督预训练角度提升视觉感知能力。
1. 端到端自动驾驶的鲁棒性
我们主要研究通过多帧的模仿学习来提升自动驾驶算法的性能。以前的多帧模仿学习往往会学习出来一些不满足因果性的模型,即自动驾驶模型行为的输出是依赖于错误的输入。例如,因果性错误的模型有时会简单地跟随前车的行为,而非自主地根据当前路况驾驶。在红绿灯突然变化的瞬间,因果错误的模型就会出现闯红灯的现象。不遵从因果性的模型会导致自动驾驶系统泛化性弱,容易在实测时候出错。
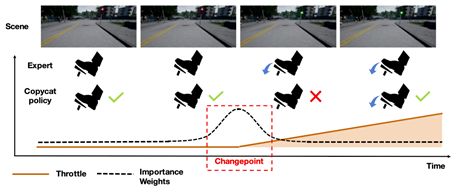
图为自动驾驶中的多帧模仿学习问题
我们系统地研究了多帧模仿学习中的因果性问题,并且提出两种解决方案,分别发表在了机器学习顶会NeurIPS和ICML上。我们大幅度提高了端到端自动驾驶模型的性能,在闯红灯、礼让行人、非异常停车等指标上有30%-60%不等的提升。与此同时,我们提出的算法对于其他场景的模仿学习、机器学习的因果性等更加基础的问题也有理论的贡献。例如,我们展示了在机器人控制环境(MuJoCo)上,同样的算法也能取得大幅度的性能提升。

图为提出的算法(Ours)相对于前人算法(BCOH)的效果
2. 高数据效率强化学习在自动驾驶中应用
自动驾驶系统在现实中会遇到许多长尾的情况。这些情况往往在自动驾驶系统最初设计的时候并没有被考虑到。而人类的驾驶者在现实中遇到这种情况的时候往往能较好的处理。长尾情况是当前自动驾驶系统落地的一大难点。为了让自动驾驶系统能够自动地学习如何处理测试中遇到的长尾问题,我们计划通过高数据效率的强化学习算法来解决这个问题。
传统的强化学习算法往往需要过多的数据,例如对应现实世界1000个小时的数据才能学会一个简单的技能。过高的数据需求使得强化学习算法在落地过程中困难重重。我们近期提出了一种具有高数据效率的强化学习算法EfficientZero可以较好地解决这个问题。在标准的Atari基准测试中,EfficientZero仅需要2个小时的数据即可达到人类的游戏水平(190% mean, 116% median 人类性能)。相比经典的DQN算法,可提升500倍数据效率。
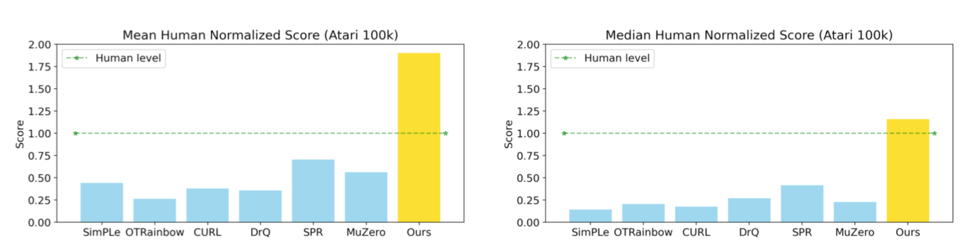
EfficientZero在Atari基准测试中效果:在少量数据下超过人类水平
我们认为在解决强化学习算法数据效率之后,强化学习算法落地的可行性大大增加。我们计划将EfficientZero等高数据效率的强化学习算法应用于自动驾驶任务。
3. 自监督视觉表征学习
自动驾驶需要在行驶过程中理解周围环境的大量语义信息,从而来帮助汽车避免潜在的危险。比如如果在行驶过程中看到了年龄较小的小孩,就需要小心通过,因为小孩可能会由于各种原因突然跑到路中央。另外例如如果看到比较少见的物体也需要进行相应的反映,例如婴儿手推车、足球、飘起来的纸片等等。
在现实世界中,不同种类的物体的数量往往巨大,很难以通过人工的方式将所有可能见到的物体都进行标注。因此自监督学习是一个重要的学习方式。自监督学习算法可以在不使用标签的情况下学习出大量的视觉概念。我们在自监督物体跟踪、对比学习的可分离性理论理解等方面都进行了深入的研究。

自监督物体跟踪:无需标签即可跟踪视频中的物体
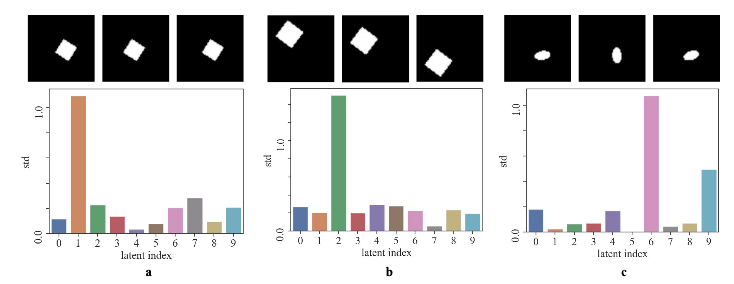
对比学习中的分组分离性质(group disentanglement)







