上海期智研究院PI,清华大学交叉信息研究院助理教授。
2019年于加州大学伯克利分校获博士学位,师从Stuart Russell教授。毕业后曾任美国OpenAI公司研究员。研究方向为提高AI系统的泛化性能,实现与人类合作交互的通用智能体。其研究成果涉及AI领域中的多个方面,包括深度强化学习,多智能体学习、自然语言理解与执行、大规模学习系统等。其论文Value Iteration Network, 曾获机器学习顶级会议NIPS2016最佳论文奖。
人机交互:研究人与AI协同的相关技术、打造下一代人机交互范式
多智能体强化学习:多智能体强化学习基础算法及应用研究
强化学习:强化学习基础算法及应用研究
机器人控制:基于强化学习算法的机器人控制
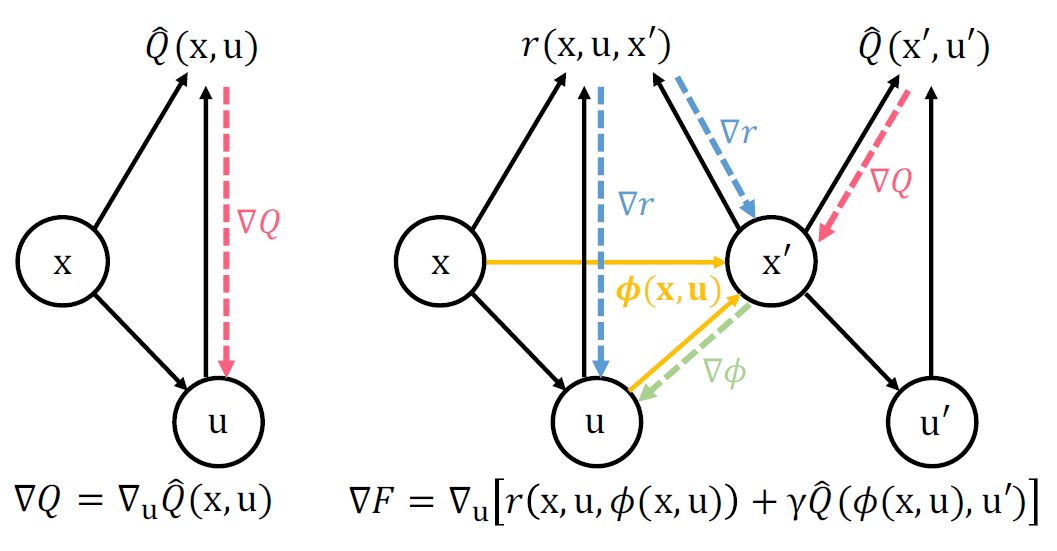
成果9:基于大语言模型的四足机器人长时任务规划控制(2025年度)
吴翼团队提出了一种基于大型语言模型与强化学习的分层控制框架,用于实现四足机器人在长时任务中的规划与控制。系统上层由语义规划、参数计算、代码生成和重规划四个LLM代理组成,能够将自然语言环境任务描述分解为带连续参数的可执行Python代码,并在执行失败或人为干预时实现闭环重规划。下层通过PPO训练了一系列运动与操控技能(包括四足/双足行走、攀爬、推箱、站立手触等),以支持细粒度的物理交互。整个系统通过上层LLM代理进行任务规划生成代码并调度下层运动技能,可完成关灯、送包裹、搭桥、乘电梯等复杂长序列任务。实验结果表明,该方法在复杂场景中能够生成合理的多步策略,性能显著优于多项基线,仿真成功率超过70%,并已在真实机器人上验证其可行性与鲁棒性。
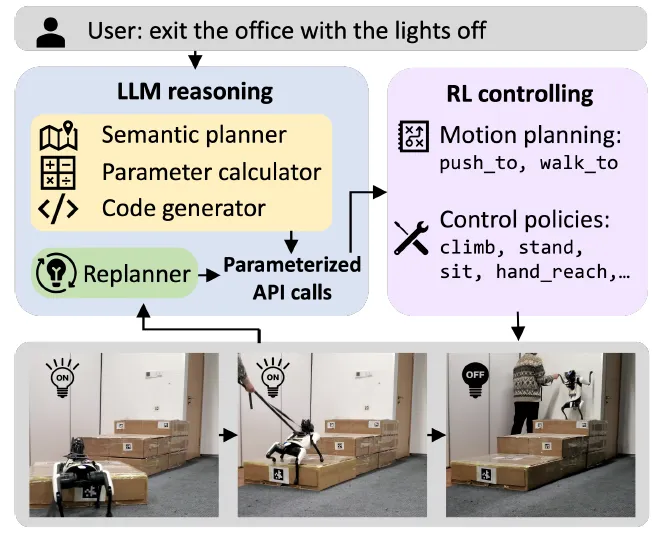
图. 面向长周期移动操作任务的分层系统概览
论文信息:
https://arxiv.org/pdf/2404.05291
Long-horizon Locomotion and Manipulation on a Quadrupedal Robot with Large Language Models, Yutao Ouyang∗, Jinhan Li∗, Yunfei Li, Zhongyu Li, Chao Yu, Koushil Sreenath, Yi Wu†,IROS 2025.
成果8:利用四足机器人团队迈向现实世界的协作与竞技足球赛(2025年度)
吴翼团队提出一种新型的多智能体强化学习(MARL)框架,用于实现更加高效的机器人足球赛团队协作。该框架通过结合低级技能训练与高层战略决策,显著提升了机器人在足球赛环境下的自主决策能力。团队采用了Fictitious Self-Play(FSP)机制,使机器人在对抗训练中逐步学习到复杂的团队合作策略,如传球、拦截以及角色分配等。通过在真实世界中部署该框架,团队成功展示了机器人能够在没有外部定位系统支持的情况下,利用板载传感器自主完成足球比赛,进一步验证了该方法的实际可行性。该研究为机器人在协作与对抗环境中的自适应行为奠定了新的基础,并为多机器人协作任务的未来发展提供了重要的技术方向。
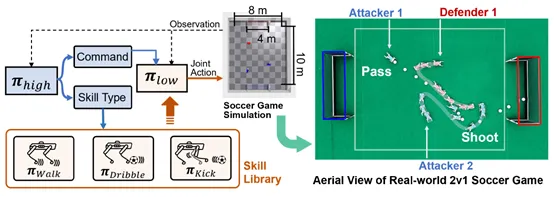
图. 分层框架包含一个高层策略(πhigh)及多个底层技能策略(πlow)
论文信息:
https://doi.org/10.48550/arXiv.2505.13834
Toward Real-World Cooperative and Competitive Soccer with Quadrupedal Robot Teams, Zhi Su*, Yuman Gao*, Emily Lukas*, Yunfei Li, Jiaze Cail, Faris Tulbah, Fei Gao, Chao Yu, Zhongyu Li†, Yi Wu†, Koushil Sreenath†,CoRL 2025.
成果7:基于迭代隐空间策略优化狼人杀中的策略语言智能体(2025年度)
吴翼团队提出了迭代隐空间策略优化算法LSPO,解决以狼人杀为代表的自然语言多智能体博弈。针对现有大模型智能体在这类博弈任务中存在固有偏好和动作空间覆盖的问题,将大模型与博弈论算法结合,逐步提升LSPO智能体策略推理与语言交互能力。在狼人杀中的实验结果表明,该方法在每次迭代中持续探索出新的策略,能显著提升智能体表现,超越现有狼人杀智能体。
论文信息:
https://arxiv.org/abs/2502.04686
Learning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization, Zelai Xu, Wanjun Gu, Chao Yu, Yi Wu†, Yu Wang†, ICML 2025
成果6:通过机器人生成数据来学习可泛化的视觉机器人操作—RST(2024年度)
在人工智能领域,基于海量数据预训练基础模型已成为一种流行趋势。然而,如何收集足够且高质量的机器人轨迹数据依然面临挑战。相比于图像或文本数据,机器人轨迹的收集更为昂贵,因为它们不仅需要涵盖机器人的状态信息,还必须包含有效的控制动作。传统方法往往依赖于人类专家进行数据收集,限制了数据的多样性和数量。
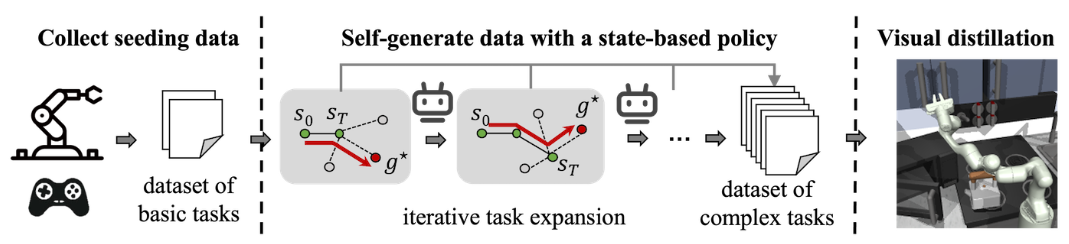
图1. RST框架概述
吴翼团队研究了这个问题,并提出一种名为“机器人自我教学”(Robot Self-Teaching, RST)的框架,使机器人能够自我生成有效且丰富的训练数据,从而减少对于人类专家采集数据的依赖。团队通过训练一个独立的数据生成策略,使机器人能够自动生成复杂性不断增加的轨迹数据。该方法首先从一个小规模的种子数据集中获取基本任务的示范,然后通过数据生成策略在状态空间中探索新任务。其关键创新在于引入了任务扩展机制,该机制利用数据生成策略的价值函数作为进展指标,逐步识别可达且具有挑战性的目标状态。通过不断发现和生成难度合适的新任务,RST框架实现了一个开放式的任务课程,使其最终学习到的视觉控制策略能够在零样本条件下,对从未见过的目标具有强组合泛化能力。

图2. 由RST框架产生的数据训练得到的可泛化操作策略在真实机器人上部署的效果
团队在两个测试平台上验证了机器人自我教学框架。在一个包含多个长方体的物块堆积任务中,该方法从最初的单块移动数据集逐步生成建筑结构。当在设计新目标结构时,最终的视觉策略在零样本测试中取得了超过40%的成功率。团队还在一个流行的离线强化学习基准“Franka厨房”中评估了此框架。其能够实现需要与厨房中四个组件互动的长期目标,而基于规划的离线强化学习基线则完全无法解决这些复杂任务。
RST框架赋予机器人在开放世界中的持续创新能力,对于自主生成机器人预训练数据有重要价值。
项目论文:Robot Generating Data for Learning Generalizable Visual Robotic Manipulation, Yunfei Li∗, Ying Yuan∗, Jingzhi Cui, Haoran Huan, Wei Fu, Jiaxuan Gao, Zekai Xu, Yi Wu†, https://irisli17.github.io/publication/iros24/rst.pdf, IROS 2024
成果5:关于LLM对齐算法的DPO和PPO的综合研究(2024年度)
近年来,大型语言模型 (LLMs) 通过在大量文本数据集上进行预训练,获得了广泛的语言模式和知识。为了更好地在各个领域利用LLM的丰富知识,一个关键挑战是如何在各式各样的下游任务中将LLM的输出和人类的偏好进行对齐。在之前的工作中,学术界和工业界广泛采用基于奖励模型的Proximal Policy Optimization (PPO) 算法和直接偏好优化 (Direct Preference Optimization,DPO) 算法。但是从没有人系统性地研究过两种算法的优劣和如何更好地利用这它们进行LLM的对齐。
吴翼团队系统性地研究了DPO,PPO等对齐算法在各种模型规模,各种任务上的优劣势。首先从理论上分析了DPO方法存在的固有缺陷,如对分布偏移敏感,可能导致学习到的策略偏向于分布之外的响应。并总结出了在实践中如何更好地利用DPO算法。通过在对话任务和代码生成任务上的实验,团队验证了提升DPO算法在LLM输出分布和偏好数据分布相差比较大时,DPO的表现会明显下降,并据此提出DPO算法在实际应用中缩小分布差距的一些方法,比如在偏好数据集上进行额外的SFT,或者进行迭代式的训练,这些方法均取得了显著成效。
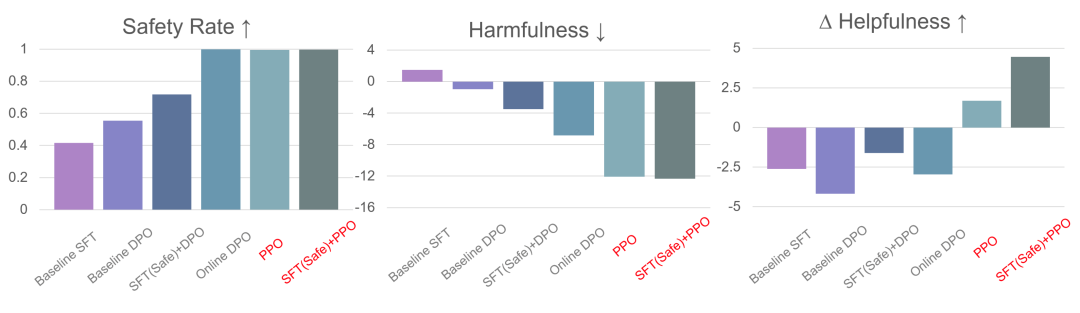
图1. PPO算法在大模型安全性评测上的表现 (对应原文Table 2)
同时,团队也提出了提升PPO算法表现的几大重要因素,即PPO训练中批大小 (Batch Size) 需要比较大;同时Advantage Normalization有助于保证训练的稳定性;最后,训练中对参考模型 (reference model) 进行缓慢更新也有助于提升LLM在下游任务的表现。
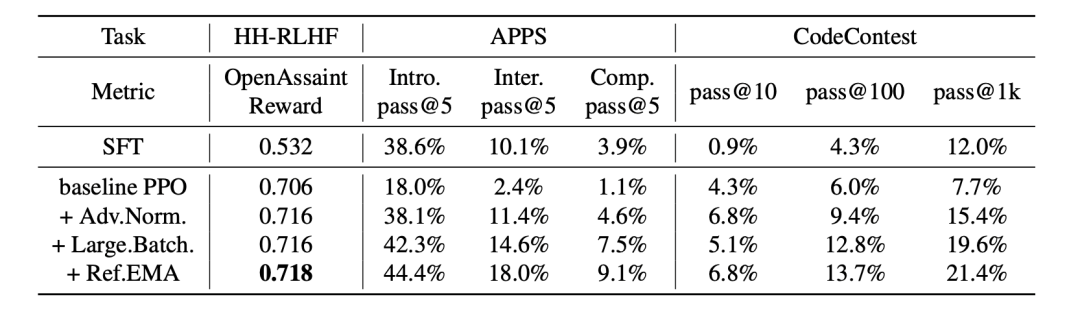
图2. 不同任务上PPO算法效果的消融研究
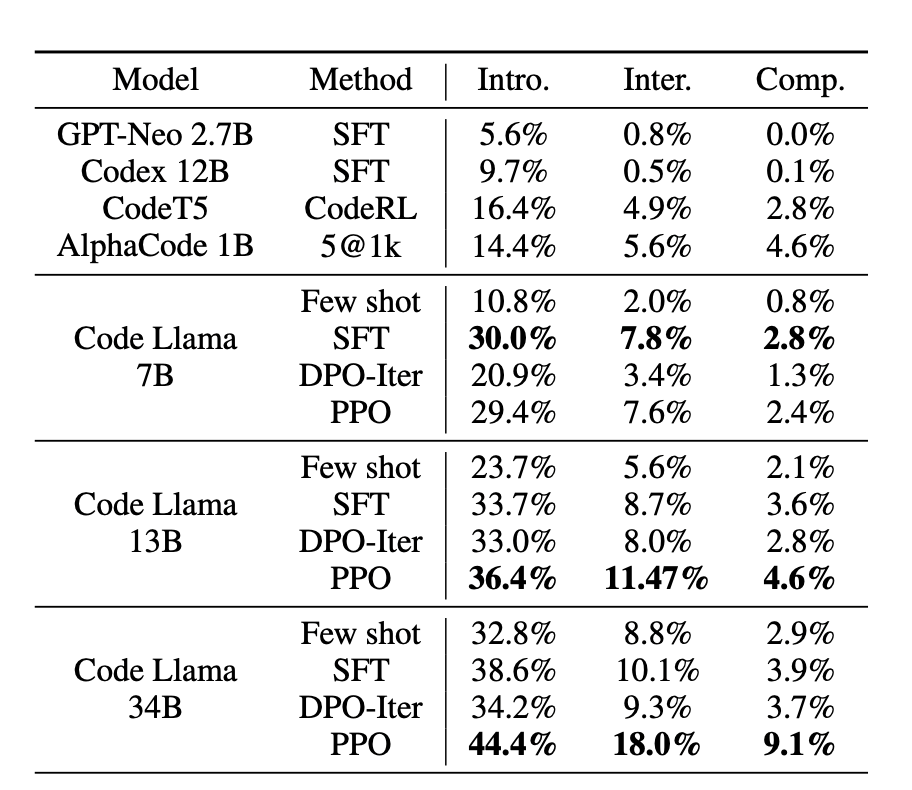
图3. 在Apps测试集上的结果
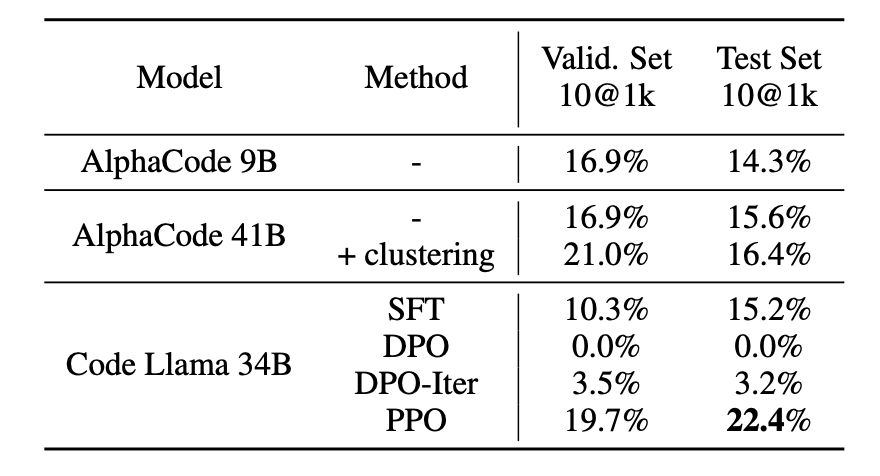
图4. 在CodeContests数据集上的通过率
最终,吴翼团队在困难的代码竞赛任务验证了算法改进的效果,并取得了SOTA的结果。该研究不仅推动了LLM对齐技术的发展,也为可信AI的研究设立了新的标杆。相关成果收录于ICML 2024中,并将进行Oral口头报告(录取率1.6%)。
项目论文:Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study, Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, Yi Wu, https://openreview.net/pdf?id=6XH8R7YrSk, Oral, ICML 2024.
成果4:四足机器人双足运动控制(2024年度)
吴翼团队在四足机器人执行类人双足运动研究中取得重要进展,提出了一个分层框架,能够响应人类视频或自然语言指令,实现模仿拳击、芭蕾舞等动作,并与人类进行物理互动。提出了LAGOON系统,它使用预训练模型生成人类动作,然后通过强化学习在模拟环境中训练控制策略,以模仿生成的人类动作,并通过领域随机化将学习到的策略部署到真实世界的四足机器人上,实现了如“后空翻”、“踢球”等复杂行为。

项目论文:Learning Agile Bipedal Motions on a Quadrupedal Robot,Yunfei Li, Jinhan Li, Wei Fu, Yi Wu,ICRA 2024
项目链接:https://sites.google.com/view/bipedal-motions-quadruped/
成果3:考虑人类偏好的人机协同(2023年度)
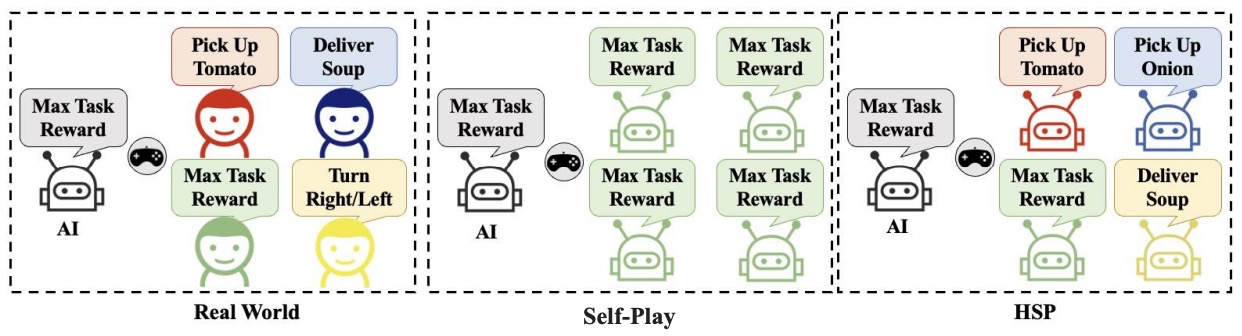
人工智能领域的长期挑战之一是建立能够与人类互动、合作和协助人类的智能体。传统的方法通常是基于模型的,即利用人类数据建立有效的行为模型,然后基于这些模型进行规划。虽然这种基于模型的方法取得了巨大的成功,但它需要昂贵和耗时的数据收集过程,而且还可能存在隐私问题。另一种思路是采用自博弈算法。首先,构建由多个自博弈训练的策略组成的多样化策略池;然后,基于这个策略池进一步训练自适应策略。尽管基于多样性策略池可以防止策略过拟合,但策略池中的每个自博弈策略仅仅是问题的一个解,要么是最优的,要么是次优的,具体取决于任务的奖励函数。这隐含着一个假设,即在任何测试条件下,智能体将精确地优化任务奖励。然而,这样的假设并不适用于与人类合作的情况。有研究表明,即使给出明确的目标,人类的效用函数也可能有很大的偏差。这表明,人类的行为可能受到一个未知的奖励函数的制约,与任务奖励有很大的不同。因此,现有的基于自博弈的两阶段框架不能有效地处理人类偏好多样的问题。
吴翼课题组提出隐效用自博弈算法(Hidden-utility Self-Play,HSP),将基于自博弈的两阶段框架扩展到考虑人类具有不同偏好的情况。HSP通过在自博弈过程中引入一个额外的隐藏奖励函数来建模人类的偏好。在第一阶段,使用奖励随机化手段构建多样性偏好策略池。基于隐效用的多样性偏好策略池可以捕捉到超出常规的、不同技能水平以及与任务奖励有关的各种可能的人类偏好。在第二阶段,基于该策略池训练得到的自适应策略可以适应具有不同偏好的未知人类。在人机协同测试环境Overcooked中对HSP进行全面的评估,从与人类模型、不同偏好人工策略、真实人类3个维度进行比较,HSP均达到最佳性能。真实人类实验结果表明,HSP可以泛化至不同偏好的人类,具有更高的人类辅助度。该成果被机器学习顶会ICLR 2023接收。
研究领域:人机协同
项目网站:https://sites.google.com/view/hsp-iclr
研究论文:Chao Yu*, Jiaxuan Gao*, Weilin Liu, Botian Xu, Hao Tang, Jiaqi Yang, Yu Wang, Yi Wu, Learning Zero-Shot Cooperation with Humans, Assuming Humans Are Biased. In International Conference on Learning Representations (ICLR), 2023. 查看PDF
------------------------------------------------------------------------------------------------------------------------------
成果2:考虑对称性的双臂协作学习(2023年度)
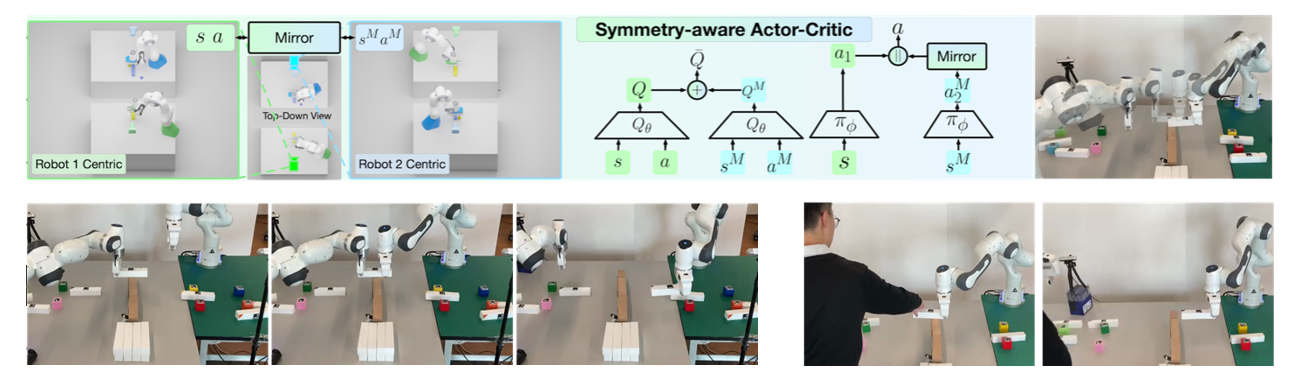
双臂机器人相比于单机械臂能解锁更丰富的技能。然而,同时控制双机械臂的决策空间显著大于只需单机械臂的场景,因此常见的强化学习算法很难从双机械臂复杂的控制空间中搜索出精准配合的策略。吴翼课题组提出了一种考虑对称性的强化学习框架,可同时控制两个机械臂协调配合,高效地完成传接多个物体的任务。
该框架的核心在于利用双臂任务中的对称性降低强化学习的决策空间,从而快速学会复杂双臂配合任务。双臂任务中,两个机械臂的角色通常是可对换的,如甲传物体给乙与乙传物体给甲策略对称,这两个对称任务可归并为同一种来学习。利用这种对称性,我们改进了Actor-Critic网络,提出了symmetry-aware结构,有效减小了强化学习的搜索空间,成功让双臂发现了在空中传接物体的策略。为了让双臂协作处理更多数量物体的重排任务,我们提出了object-centric relabeling技术做数据增强,来产生更多样的部分成功数据。综合以上技术,我们成功地让两个机械臂高效协作完成8个物体的重排任务。
我们将训练出的策略部署在两个固定在不同工作区的Franka Panda机械臂上。我们的强化学习策略既可以让两只机械臂各自拾取物体放置到本侧工作区,也能协调双臂彼此配合,把物体从一侧传接到另一侧。此外,我们还可以在测试时将一只机械臂替换为人,应用到人机协作场景中。该成果被机器人领域顶会ICRA 2023接收。
研究领域:机器人控制
项目网站:https://sites.google.com/view/bimanual
研究论文:Yunfei Li*, Chaoyi Pan*, Huazhe Xu, Xiaolong Wang, Yi Wu, Efficient Bimanual Handover and Rearrangement via Symmetry-Aware Actor-Critic Learning. In 2023 IEEE International Conference on Robotics and Automation (ICRA) (pp. 3867-3874). IEEE. 查看PDF
------------------------------------------------------------------------------------------------------------------------------
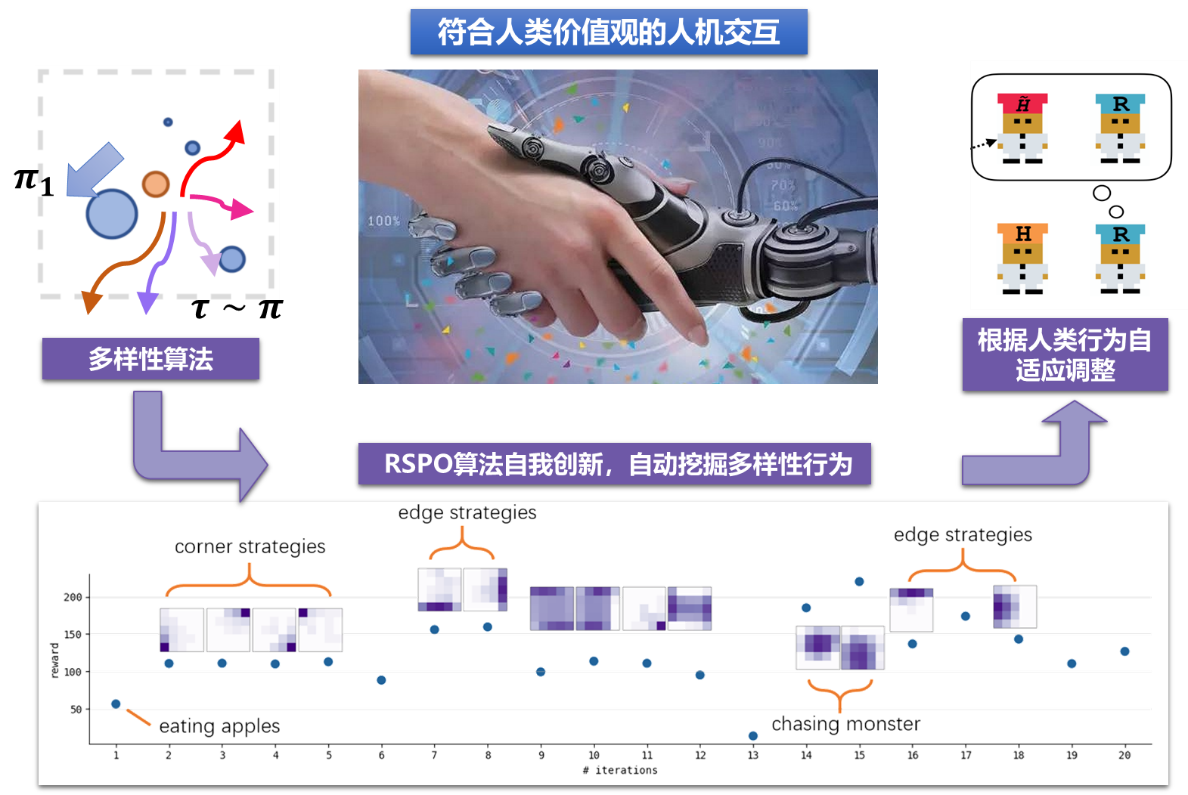
成果1:基于多样性的自适应智能决策(2022年度)
传统智能决策算法均基于最优性假设,即:在设定目标下求解最优策略并执行最优动作。然而最优性假设却并适用于需要与人类交互的协作场景。其根本问题是,人类的行为几乎从来不是最优的。因此人工智能必须认识到人类行为的多样性,并根据人类行为自适应调整决策,来帮助人类完成其目标。吴翼团队在领域内首次提出了多样性学习框架,从经典最优决策假设更进一步,要求智能体不光要解决问题,更要自我探索与创新,用尽量多不同的合理的拟人行为解决问题——即“不光要赢,还要赢的精彩”。基于多样性决策框架,吴翼团队还提出了多个多样性强化学习算法,并开源了多智能体决策代码库MAPPO。目前团队开发的多样性学习框架,是领域内首个能够在机器人控制、星际争霸、多人足球游戏等多个复杂任务场景中,都能自动探索出多样性策略行为的算法框架。同时,基于多样性策略为进行自我博弈训练,实现在miniRTS,overcooked等多个复杂人机合作场景中SOTA的表现,并且在真人测试中大幅超越目前领域内最好的泛化性强化学习算法,首次实现了在复杂游戏中与真人的智能协作,朝着让人工智能真正走进千家万户的最终目标,迈出了坚实的一步。团队系列成果发表于机器学习顶级会议ICLR2022、ICML2022、NeurIPS2022等,其中发表于NeurIPS2022的开源算法库MAPPO至今已经获得超过250次引用,受到领域内广泛关注。



38. Learning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization, Zelai Xu, Wanjun Gu, Chao Yu, Yi Wu†, Yu Wang†, ICML 2025
37. Toward Real-World Cooperative and Competitive Soccer with Quadrupedal Robot Teams, Zhi Su*, Yuman Gao*, Emily Lukas*, Yunfei Li, Jiaze Cail, Faris Tulbah, Fei Gao, Chao Yu, Zhongyu Li†, Yi Wu†, Koushil Sreenath†,CoRL 2025.
36. Long-horizon Locomotion and Manipulation on a Quadrupedal Robot with Large Language Models, Yutao Ouyang∗, Jinhan Li∗, Yunfei Li, Zhongyu Li, Chao Yu, Koushil Sreenath, Yi Wu†,IROS 2025.
35. Robot Generating Data for Learning Generalizable Visual Robotic Manipulation, Yunfei Li∗, Ying Yuan∗, Jingzhi Cui, Haoran Huan, Wei Fu, Jiaxuan Gao, Zekai Xu, Yi Wu†, https://irisli17.github.io/publication/iros24/rst.pdf, IROS 2024.
34. Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study, Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, Yi Wu, https://openreview.net/pdf?id=6XH8R7YrSk, Oral, ICML 2024.
33. Language Agents with Reinforcement Learning for Strategic Play in the Werewolf Game, Zelai Xu, Chao Yu, Fei Fang, Yu Wang, Yi Wu, https://arxiv.org/pdf/2310.18940, ICML 2024.
32. Adaptive-Gradient Policy Optimization: Enhancing Policy Learning in Non-Smooth Differentiable Simulations,Feng Gao*, Liangzhi Shi*, Shenao Zhang, Zhaoran Wang, Yi Wu,https://openreview.net/pdf?id=S9DV6ZP4eE, ICML 2024.
31. Yunfei Li, Jinhan Li, Wei Fu, Yi Wu, Learning Agile Bipedal Motions on a Quadrupedal Robot, ICRA 2024
30. Shusheng Xu, Huaijie Wang, Jiaxuan Gao, Yutao Ouyang, Chao Yu, Yi Wu, Language-Guided Generation of Physically Realistic Robot Motion and Control, ICRA 2024
29. Zhiyu Mei*, Wei Fu*, Jiaxuan Gao, Guangju Wang, Huanchen Zhang, & Yi Wu, SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores. ICLR 2024
28. Weihua Du*, Jinglun Zhao*, Chao Yu, Xingcheng Yao, Zimeng Song, Siyang Wu, Ruifeng Luo, Zhiyuan Liu, Xianzhong Zhao, Yi Wu, Automatics Truss Design with Reinforcement Learning, International Joint Conference on Artificial Intelligence (IJCAI), 2023 查看PDF
27. Zhiyu Mei, Wei Fu, Guangju Wang, Huanchen Zhang, Yi Wu, SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores, ICML Workshop, 2023 查看PDF
26. Zelai Xu, Yancheng Liang, Chao Yu, Yu Wang and Yi Wu, Fictitious Cross-Play: Learning Nash Equilibrium in Mixed Cooperative-Competitive Games, International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2023 查看PDF
25. Yixuan Mei, Jiaxuan Gao, Weirui Ye, Shaohuai Liu, Yang Gao, Yi Wu, SpeedyZero: Mastering Atari with Limited Data and Time, International Conference on Learning Representation (ICLR), 2023 查看PDF
24. Wei Fu, Weihua Du, Jingwei Li, Sunli Chen, Jingzhao Zhang, Yi Wu, Iteratively Learn Diverse Strategies with State Distance Information, Conference on Neural Information Processing Systems (NeurIPS), 2023 查看PDF
23. Yunfei Li*, Chaoyi Pan*, Huazhe Xu, Xiaolong Wang, Yi Wu, Efficient Bimanual Handover and Rearrangement via Symmetry-Aware Actor-Critic Learning, International Conference on Robot Automation (ICRA), 2023 查看PDF
22. Chao Yu*, Xinyi Yang*, Jiaxuan Gao*, Jiayu Chen, Yunfei Li, Jijia Liu, Yunfei Xiang, Ruixin Huang, Huazhong Yang, Yi Wu and Yu Wang, Asynchronous Multi-Agent Reinforcement Learning for Efficient Real-Time Multi-Robot Cooperative Exploration, International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2023 查看PDF
21. Jing Wang*, Meichen Song*, Feng Gao*, Boyi Liu, Zhaoran Wang and Yi Wu, Differentiable Arbitrating in Zero-sum Markov Games, International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2023 查看PDF
20. Chao Yu*, Jiaxuan Gao*, Weilin Liu, Botian Xu, Hao Tang, Jiaqi Yang, Yu Wang, Yi Wu, Learning Zero-Shot Cooperation with Humans, Assuming Humans Are Biased, International Conference on Learning Representation (ICLR), 2023 查看PDF
19. Shusheng Xu, Yancheng Liang, Yunfei Li, Simon Shaolei Du, Yi Wu, Beyond Information Gain: An Empirical Benchmark for Low-Switching-Cost Reinforcement Learning, Transactions on Machine Learning Research (TMLR), 2023 查看PDF
18. Shusheng Xu, Xingxing Zhang, Yi Wu, Furu Wei, Sequence Level Contrastive Learning for Text Summarization, Association for the Advancement of Artificial Intelligence (AAAI), 2022 查看PDF
17. Yunfei Li, Tao Kong, Lei Li, Yi Wu, Learning Design and Construction with Varying-Sized Materials via Prioritized Memory Resets, International Conference on Robot Automation (ICRA), 2022 查看PDF
16. Zihan Zhou*, Wei Fu*, Bingliang Zhang, Yi Wu, Continuously Discovering Novel Strategies via Reward-Switching Policy Optimization, International Conference on Learning Representation (ICLR), 2022 查看PDF
15. Yunfei Li*, Tian Gao*, Jiaqi Yang, Huazhe Xu, Yi Wu, Phasic Self-Imitative Reduction for Sparse-Reward Goal-Conditioned Reinforcement Learning, International Conference on Machine Learning (ICML), 2022 查看PDF
14. Chao Yu*, Xinyi Yang*, Jiaxuan Gao*, Huazhong Yang, Yu Wang, Yi Wu, Learning Efficient Multi-Agent Cooperative Visual Exploration, European Conference on Computer Vision (ECCV), 2022 查看PDF
13. Zhecheng Yuan*, Zhengrong Xue*, Bo Yuan, Xueqian Wang, Yi Wu, Yang Gao, Huazhe Xu, Pre-Trained Image Encoder for Generalizable Visual Reinforcement Learning, Conference on Neural Information Processing Systems (NeurIPS), 2022 查看PDF
12. Shusheng Xu, Huaijie Wang, Yi Wu, Grounded Reinforcement Learning: Learning to Win the Game under Human Commands, Conference on Neural Information Processing Systems (NeurIPS), 2022 查看PDF
11. Zhenggang Tang*, Chao Yu*, Boyuan Chen, Huazhe Xu, Xiaolong Wang, Fei Fang, Simon Shaolei Du, Yu Wang, Yi Wu, Discovering Diverse Multi-Agent Strategic Behavior via Reward Randomization, International Conference on Learning Representation (ICLR), 2022 查看PDF
10. Yunfei Li, Yilin Wu, Huazhe Xu, Xiaolong Wang, Yi Wu, Solving Compositional Reinforcement Learning Problems via Task Reduction, International Conference on Learning Representation (ICLR), 2022 查看PDF
9. Weizhe Chen*, Zihan Zhou*, Yi Wu, Fei Fang, Temporal Induced Self-Play for Stochastic Bayesian Games, International Joint Conference on Artificial Intelligence (IJCAI), 2022 查看PDF
8. Yunfei Li, Tao Kong, Lei Li, Yifeng Li, Yi Wu, Learning to Design and Construct Bridge without Blueprint, International Conference on Intelligent Robots and Systems (IROS), 2022 查看PDF
7. Shusheng Xu*, Yichen Liu*, Xiaoyu Yi, Siyuan Zhou, Huizi Li, Yi Wu, Native Chinese Reader: A Dataset Towards Native-Level Chinese Machine Reading Comprehension, Conference on Neural Information Processing Systems (NeurIPS), 2022 查看PDF
6. Tianjun Zhang, Huazhe Xu, Xiaolong Wang, Yi Wu, Kurt Keutzer, Joseph E. Gonzalez, Yuandong Tian, NovelD: A Simple yet Effective Exploration Criterion, Conference on Neural Information Processing Systems (NeurIPS), 2022 查看PDF
5. Shusheng Xu, Xingxing Zhang, Yi Wu, Furu Wei, Ming Zhou, Unsupervised Extractive Summarization by Pre-training Hierarchical Transformers, Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022 查看PDF
4. Ruihan Yang, Huazhe Xu, Yi Wu, Xiaolong Wang, Multi-Task Reinforcement Learning with Soft Modularization, Conference on Neural Information Processing Systems (NeurIPS), 2022 查看PDF
3. Wei Fu, Chao Yu, Zelai Xu, Jiaqi Yang, Yi Wu, Revisiting Some Common Practices in Cooperative Multi-Agent Reinforcement Learning, International Conference on Machine Learning (ICML), 2022 查看PDF
2. Chao Yu*, Akash Velu*, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, Yi Wu, The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games, Conference on Neural Information Processing Systems (NeurIPS), 2022 查看PDF
1. Jiayu Chen, Yuanxin Zhang, Yuanfan Xu, Huimin Ma, Huazhong Yang, Jiaming Song, Yu Wang, Yi Wu, Variational Automatic Curriculum Learning for Sparse-Reward Cooperative Multi-Agent Problems, Conference on Neural Information Processing Systems (NeurIPS), 2021 查看PDF