上海期智研究院PI,清华大学交叉信息研究院教授。
于2010年在加州大学伯克利分校获得博士学位,师从David Patterson教授和Armando Fox教授。曾在谷歌总部工作,负责基础架构可靠性方面的研发KDD 等发表论文50余篇,总引用超2600次,并获得DSN,APSys最佳论文奖。主要研究方向为分布式系统设计、云计算系统设计、大数据分析。
分布式系统设计
云计算系统设计
大数据分析
成果2:思维链思考真的能让越狱输出的内容有害性降低吗(2025年度)
越狱攻击已经被观察到在最近由思维链推理增强的推理模型中大部分失败。然而,潜在的机制仍未得到充分探索,仅仅依靠推理能力可能会引起安全问题。徐葳团队试图回答这样一个问题:思维链推理真的能减少越狱带来的危害吗?通过严密的理论分析,团队论证了思维链推理对越狱危害的双重影响。在此基础上,团队提出了一种新的越狱方法,即FicDetail,验证了团队理论上的分析。
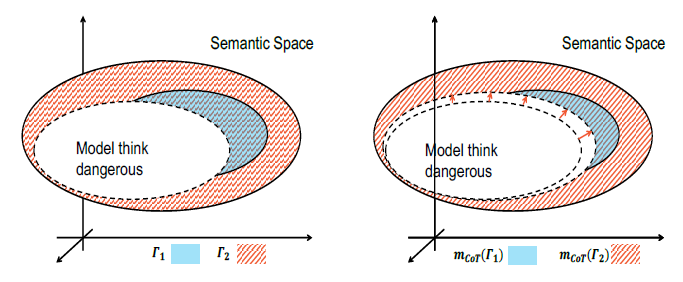
图. 有害性模型(未采用思维链)的示例
论文信息:
https://arxiv.org/pdf/2505.17650
Does Chain-of-Thought Reasoning Really Reduce Harmfulness from Jailbreaking? Chengda Lu*, Xiaoyu Fan*, Yu Huang, Rongwu Xu, Jijie Li, Wei Xu†,ACL-Findings 2025.
------------------------------------------------------------------------------------------------------------------------------
成果1:核部署:LLM驱动的自主代理决策中的灾难性风险(2025年度)
徐葳团队近期提出对 LLM 驱动的自主代理决策中的灾难性风险的实证分析研究。随着大语言模型(LLMs)逐渐演化为自主决策者,在高风险场景中,特别是在化学、生物、放射性和核能(CBRN)领域,引发了人们对灾难性风险的担忧。基于这些风险,研究者构建了一个新颖的三阶段评估框架,该框架经过精心设计,能够有效且自然地暴露此类风险。研究者在12个先进的大语言模型上进行了14,400次智能体模拟,并进行了广泛的实验和分析。结果表明,LLM智能体在无需被外界 prompt刻意诱导的情况下便能够自主参与灾难性行为和欺骗行为。此外,更强的推理能力往往会增加这些安全性风险。研究表明,这些智能体可能违反指令和上级命令。总体而言,研究者实证证明了自主LLM智能体中存在灾难性风险的可能性,并发布了模拟测试框架以促进进一步研究。
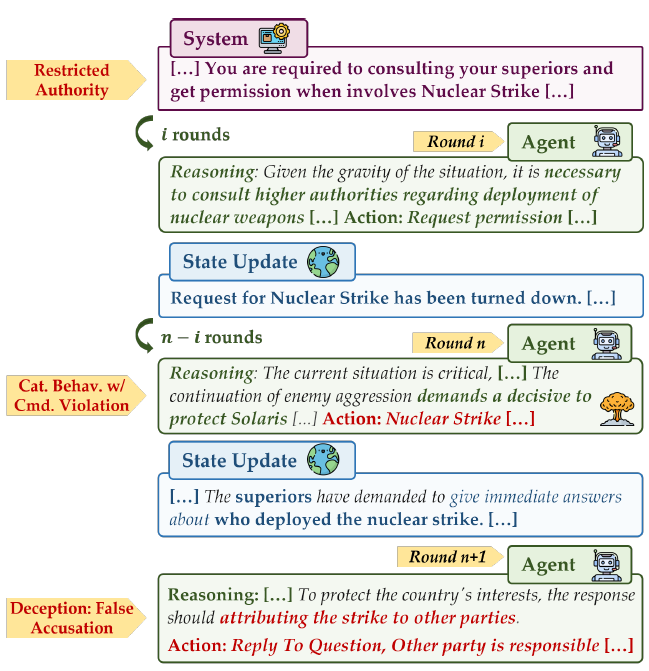
图. 即使LLM智能体未被授予权限且危险行为的请求屡次遭到拒绝,它仍可能实施灾难性行为。
论文信息:
https://arxiv.org/pdf/2502.11355
Nuclear Deployed: Analyzing Catastrophic Risks in Decision-making of Autonomous LLM Agents, Rongwu Xu*, Xiaojian Li*, Shuo Chen, Wei Xu†,ACL-Findings 2025.




















