上海期智研究院PI,清华大学交叉信息研究院助理教授。
于美国加州大学伯克利分校获得博士学位,师从Trevor Darrell教授。在获得博士学位后,于加州伯克利大学与Pieter Abbeel等人合作完成了博士后研究。研究方向为强化学习与机器人学。高阳博士目前主持具身视觉与机器人实验室 (Embodied Vision and Robotics,简称EVAR Lab),专注于利用人工智能技术赋能机器人,致力于打造通用的具身智能框架,提出了一系列高效通用的算法框架如Efficient zero、ViLa、CoPa等。
个人荣誉
北京市青年托举计划
机器人:研究通用机器人的算法
强化学习:高样本效率、现实世界的强化学习
成果14:针对第一人称人类视频的无监督单目4D场景重建(2025年度)
高阳团队提出EgoMono4D模型,在第一人称人类视频上首次实现了基于无监督方法训练的快速单目4D场景重建。通过无监督算法设计,该模型的训练仅需纯RGB视频数据,而无需任何数据标签。基于此方法,团队在超过一千万帧第一人称视频上进行大规模训练,得到了首个高质量的、端到端的、重建速度极快的人类视频重建模型。评估结果现实,虽然不依赖于任何真实标签进行训练,EgoMono4D模型在第一人称人类视频重建任务上取得了SoTA的表现。该成果首次证明,互联网海量日常人像视频可被直接转化为可驱动4D 数据资产,为具身智能、AR/VR 内容生产与元宇宙数据引擎提供了低成本、可扩展的新范式。
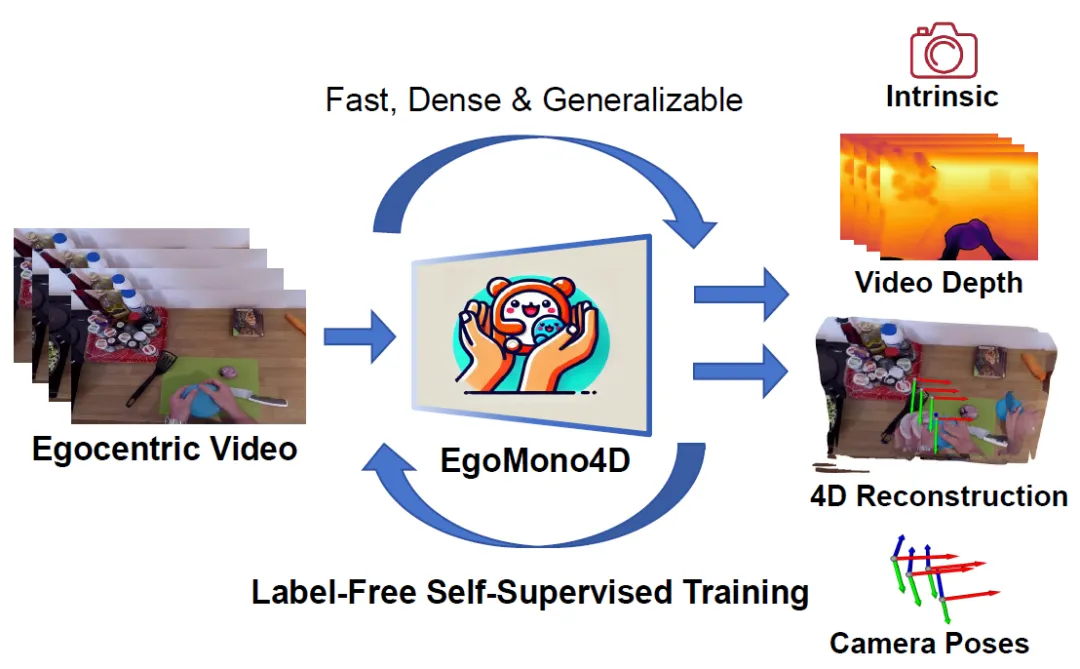
图. EgoMono4D:以第一人称视角场景的快速密集4D重建
论文信息:
https://arxiv.org/pdf/2411.09145
Self-Supervised Monocular 4D Scene Reconstruction for Egocentric Videos, Chengbo Yuan, Geng Chen, Li Yi, Yang Gao†,ICCV 2025.
-----------------------------------------------------------------------------------------------
成果13:基于视觉语言模型的自模仿学习(2025年度)
高阳团队提出RoboCoT: 基于视觉语言模型的自模仿学习。传统利用VLM作为奖赏激励智能体学习的方法往往基于粗糙的语言引导,例如“打开门”。然而人类的学习过程中往往家长会采用更加细致的语言来指导孩子学会某项技能,例如“将右手靠近门把手”,“向左转动门把手”等。甚至家长会在这个过程中给出一些潜在的失败教训,例如“不要将手卡在门把手的右侧“等。RoboCoT基于更加细粒度的语言描述设计了稠密的奖赏信号提供给智能体实现高效探索;在探索过程中,RoboCoT利用VLM收集成功的轨迹提升学习效率。实验表明RoboCoT性能大幅度超过基线方法,在 10项Meta-World任务上的平均成功率是RoboCLIP的5.4倍。
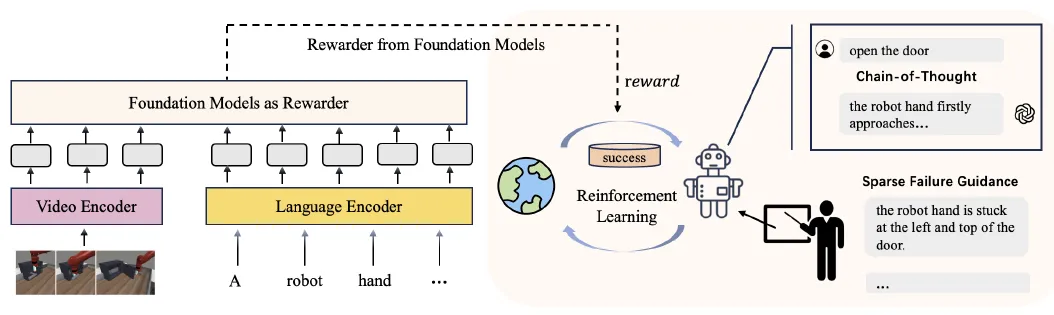
图. 基于视觉语言模型的自模仿学习
论文信息:
https://arxiv.org/pdf/2405.13573
Learning Manipulation Skills through Robot Chain-of-Thought with Sparse Failure Guidance, Kaifeng Zhang, Zhao-Heng Yin, Weirui Ye, Yang Gao†,IROS 2025.
-----------------------------------------------------------------------------------------------
成果12:RoboEngine: 即插即用型视觉机器人数据增强工具包(2025年度)
高阳团队提出RoboEngine视觉增强工具包:只在一个背景中收集机器人数据,结合视觉数据增强,就能让训练得到的机器人策略泛化到几乎任何背景。团队首先提出RoboSeg数据集,首个高质量/高多样性的机器人分割掩码数据集。通过在该数据集微调基础模型,团队得到RoboSAM分割模型,来获取机器人的准确分割掩码;任务相关物体的分割使用GroundingSAM基础模型。然后,团队在RoboSeg数据集微调图像生成模型,得到给定机器人/任务相关物体的前提下,生成高质量/高保真背景的Diffusion模型,从而完成机器人数据的视觉增强。试验结果表明,RoboEngine能够让机器人策略在全新环境成功率翻三倍(200%增幅)。并且,团队将整个Pipeline封装,使得后续用户可以使用几行代码就达到上述效果,实现了类似计算机视觉领域ColorJitter的即插即用效果。
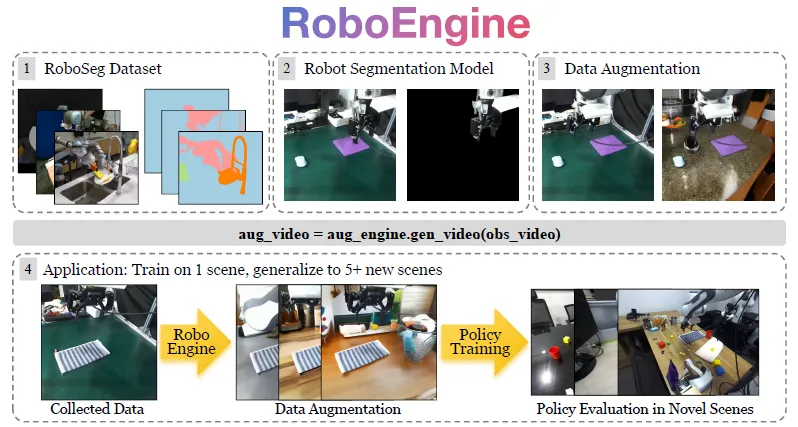
图. RoboEngine—首个即插即用型视觉机器人数据增强工具包
论文信息:
https://arxiv.org/pdf/2503.18738
RoboEngine: Plug-and-Play Robot Data Augmentation with Semantic Robot Segmentation and Background Generation, Chengbo Yuan*, Suraj Joshi*, Shaoting Zhu*, Hang Su, Hang Zhao, Yang Gao†,IROS 2025.
-----------------------------------------------------------------------------------------------
成果11:人形机器人极限平衡能力学习(2025年度)
高阳团队提出HuB (Humanoid Balance),一个极限人形机器人平衡控制统一框架。该方法针对三大挑战:参考动作误差引发的不稳定性、人机形态差异导致的学习困难、以及由传感器噪声和未建模动力学带来的仿真到现实差距。HuB通过动作参考修正、平衡感知策略学习与鲁棒性训练三个模块协同解决上述问题。在Unitree G1人形机器人上的实验表明,HuB 能够在李小龙踢腿、燕式平衡等极限静态平衡任务中保持稳定,即便遭受强烈外部扰动(如高速足球冲击)仍能迅速恢复。

图. HuB在Unitree G1机器人上完成极限平衡任务
论文信息:
https://arxiv.org/abs/2505.07294
HuB: Learning Extreme Humanoid Balance, Tong Zhang*, Boyuan Zheng*, Ruiqian Nai, Yingdong Hu, Yen-Jen Wang, Geng Chen, Fanqi Lin, Jiongye Li, Chuye Hong, Koushil Sreenath, Yang Gao†,CoRL 2025.
---------------------------------------------------------------------------------------------------------------
成果10:KineDex:通过触觉增强的示教采集与学习,实现机器人灵巧操作(2025年度)
高阳团队提出 KineDex 框架,面向灵巧操作任务探索触觉增强的示教与策略学习新方法。传统遥操方法常受制于运动学差异与缺乏力反馈,导致采集数据质量不足。KineDex引入手把手的运动示教方式,使操作员动作可直接传递到灵巧手,并同步采集高保真触觉信号。为解决视觉遮挡问题,团队采用图像修复技术预处理数据,并在此基础上训练融合视觉与触觉的策略网络,结合力控制实现精细的接触操作。在瓶盖旋紧、牙膏挤压、注射器按压等九项复杂任务中,KineDex 平均成功率达74.4%,远超无力控制方案的16.7%,且示教效率较遥操提升两倍以上。

图. KineDex框架实现灵巧操作任务
论文信息:
https://doi.org/10.48550/arXiv.2505.01974
KineDex: Learning Tactile-Informed Visuomotor Policies via Kinesthetic Teaching for Dexterous Manipulation, Di Zhang*, Chengbo Yuan, Chuan Wen, Hai Zhang, Junqiao Zhao, Yang Gao†,CoRL 2025.
-----------------------------------------------------------------------------------------------
成果9:微调难以模拟的四足机器人运动目标:总功耗节约案例研究(2025年度)
足式机器人在复杂环境中的移动能力备受关注,然而,其实际应用不仅要求高机动性,更对能源效率、安全性、用户体验等关键性能提出了严格要求。在当前的机器人研发中,一个核心挑战在于许多重要的性能指标(例如电池的实际总功耗、机器人运动时产生的噪音、部件的长期磨损等)难以在仿真环境中被精确建模。传统的机器人学习方法高度依赖sim-to-real的迁移范式,即在仿真器中训练控制策略,然后部署到真实机器人上。但由于仿真器主要关注动力学和运动学,对上述难以模拟的真实世界因素的缺失或不准确建模,导致基于仿真的优化效果不佳,甚至无法解决这些问题。研究人员尝试使用手工设计的代理指标(如理想机械功率、足部接触力)来间接优化这些目标,但这类代理往往与特定问题高度绑定,且准确性有限,需要大量的专家知识和繁琐的参数调整。
为解决这一核心难题,本研究提出了一种创新的数据驱动框架,专门用于精细调优机器人(特别是四足机器人)在复杂运动控制中那些难以在仿真环境中精确模拟的性能目标,并以总功耗节省作为了核心案例进行了深入研究和验证。
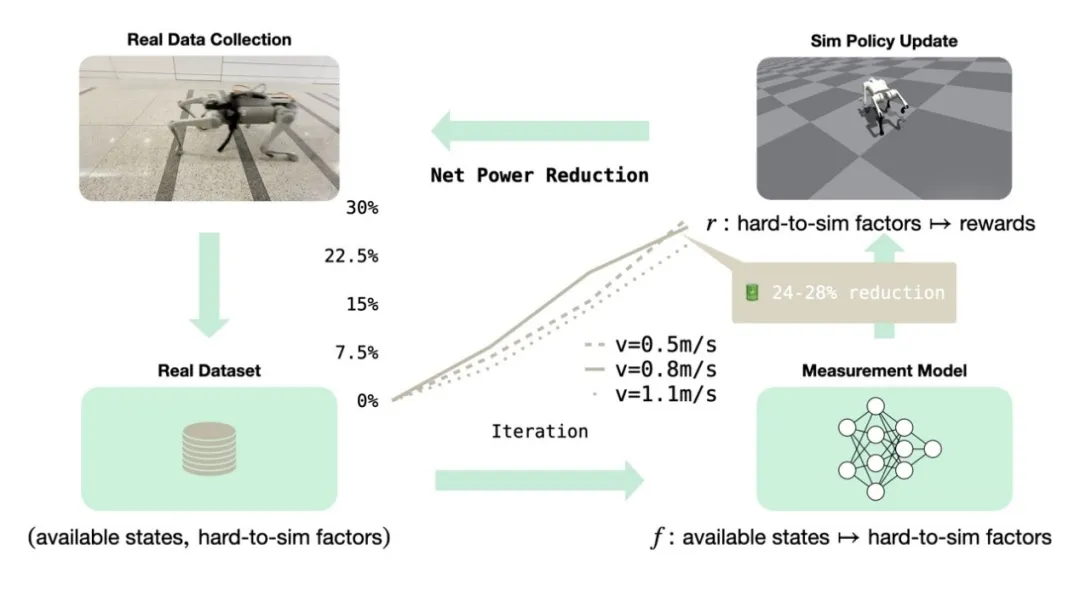
该框架的核心创新在于其数据驱动的“测量模型”构建与迭代优化流程。具体而言,算法流程如下:
(1) 真实数据收集:使用一个预训练好的基础策略或上一轮迭代中选出的最优策略,在真实的四足机器人上执行任务(如按指令速度行走),并同步收集机器人在仿真中可观测的状态数据(如电机扭矩、关节角速度)以及对应的真实世界中难以模拟的性能指标数据(如从电池组实际消耗的总电流)。
(2) 测量模型训练:利用收集到的成对数据(仿真可观状态 vs. 真实性能指标),训练一个数据驱动的测量模型。该模型的目标是学习从仿真可观状态到真实性能指标的映射关系。例如,根据电机的扭矩和角速度来预测瞬时总电流。所有先前迭代收集的数据都会被累积用于训练,以增强模型的泛化能力和数据多样性。
(3) 仿真环境中的策略精调:将训练好的测量模型集成到仿真环境中,用以估算在特定状态下机器人可能产生的真实功耗(或其他难以模拟的指标)。这个估算值随后被整合进强化学习的奖励函数中,使得策略在仿真训练时,不仅优化其基本运动任务(如跟踪指令速度),同时也直接优化这个与真实世界性能紧密相关的“难以模拟目标”。为防止策略过度利用当前可能尚不完美的测量模型,以及避免因数据分布漂移导致模型预测失效,算法中引入了KL散度惩罚项,以约束策略更新的幅度,使其与收集数据时的策略(锚点策略)保持一定的相似性。
(4) 分层策略选择与迭代:在仿真中通过参数扫描(如调整不同奖励项的权重、KL散度惩罚系数)生成一批候选策略。首先,基于这些策略在仿真环境中的性能(包含对难以模拟目标的优化效果)筛选出一组精英策略。然后,将这组精英策略部署到真实机器人上进行评估,根据其在真实世界中的实际表现(如真实总功耗)选出当前轮次的最优策略。该最优策略将作为下一轮迭代的锚点策略之一,同时其在真实评估中产生的数据也将被加入数据库,用于进一步优化测量模型。
通过这一迭代循环(数据收集 -> 模型更新 -> 仿真调优 -> 真实评估与选择),策略和测量模型共同进化,逐步逼近真实世界中的最优性能。
研究团队以四足机器人的总功耗节省为目标,对该框架进行了实验验证。结果显示,相较于使用传统解析模型(如理想机械功率加电机焦耳热)作为优化代理的基线方法,本研究提出的数据驱动框架取得了显著的性能提升。在不同速度下,机器人实现了24%至28%的净总功耗降低(在减去机器人待机功耗后,与预训练策略相比)。这不仅显著延长了机器人的单次充电工作时长,而且观察到机器人在行为层面也发生了积极变化,例如关节扭矩输出更平滑,前腿站姿更自然(更靠近身体重心),从而提升了运动的整体能效。在模拟真实场景的室内外长距离行走测试中,经该框架优化的策略也展现出更优的电池续航保持能力。
该工作提出并验证了一种富有前景的机器人学习与控制框架,它通过巧妙地结合数据驱动建模与迭代式仿真精调,有效攻克了四足机器人在总功耗等难以模拟目标上的优化难题,为提升复杂机器人在真实环境中的综合性能开辟了新途径。
---------------------------------------------------------------------------------------------------------------
成果8:机器人操作模仿学习的数据扩展定律(2025年度)
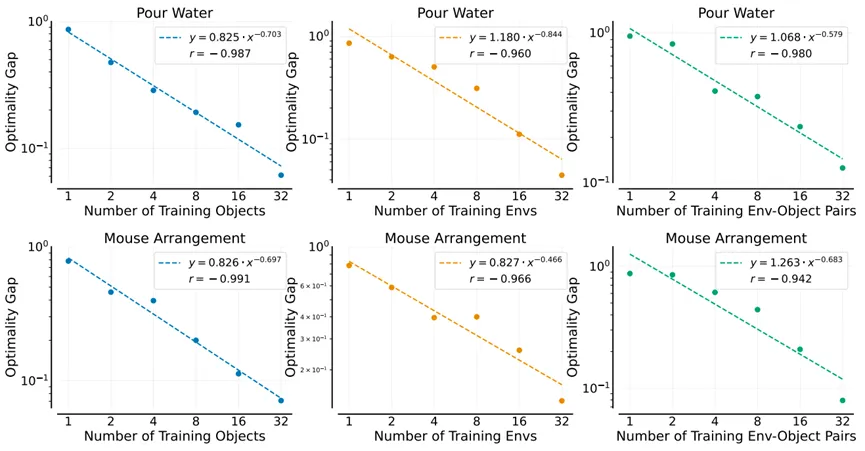
图. 幂律关系
数据扩展已在自然语言处理和计算机视觉等领域引发深刻变革,赋予模型出色的泛化能力。文章旨在探究机器人领域,特别是机器人物体抓取任务中是否存在类似的数据扩展定律,以及通过恰当的数据扩展,单任务机器人策略是否能在面对同一类别中的任意对象和任意环境时实现零样本部署。现有的机器人策略大多缺乏这种零样本泛化能力。

图. 真机实验任务
为了回答上述问题,研究团队对模仿学习中的数据扩展进行了全面的实证研究。通过在大量环境和不同对象中收集数据,研究团队系统地研究了单任务策略在面对新环境或新对象时,其性能如何随训练环境或物体数量的增加而变化。研究团队还考察了在环境和物体数量固定的情况下,演示数量对策略泛化能力的影响。研究团队使用手持式抓手 (UMI) 在各种环境和不同对象上收集人类演示数据,并使用 Diffusion Policy 对数据进行建模。研究团队首先聚焦于“倒水”和“整理鼠标”这两个任务进行案例研究,深入分析了策略泛化能力随环境、对象和演示数量的变化,并总结了数据扩展定律。研究发现,如代表图中所示,策略对新对象、新环境或两者的泛化能力与训练对象、训练环境或训练环境-对象对的数量大致呈幂律关系。相比之下,当环境和物体数量固定时,演示数量与策略泛化性能之间没有明显的幂律关系。性能最初随演示数量增加而快速提升,但随后会趋于平稳。

图.数据展示
研究团队的研究收集了超过40,000个演示,并在严格的评估协议下执行了超过15,000次真实世界机器人操作。实验结果揭示了多项有趣的发现:策略对环境和对象的多样性依赖远大于绝对的演示数量。一旦每个环境或对象的演示数量达到某个阈值,增加更多演示的效果微乎其微。基于这些洞察,研究团队提出了一种高效的数据收集策略。研究团队将该策略应用于“折叠毛巾”和“拔充电器”这两个新任务。通过四名数据收集者一个下午的工作,研究团队收集了充足的数据,使得这四个任务的策略在包含未见物体的全新环境中实现了约90%的成功率。这凸显了研究团队数据收集策略的高效性,并表明训练一个能够在新环境和对象中实现零样本部署的单任务策略所需的时间和成本是适度的。研究团队还初步探索模型尺寸扩展,发现视觉编码器的尺寸扩展可以显著提升性能。
------------------------------------------------------------------------------------------------------------------------------
成果7:一种通往具身智能体高效率与自主学习的框架(2024年度)
基于大模型先验知识的强化学习(Reinforcement Learning with Foundation Priors, RLFP) 框架为机器人在复杂操作任务中的学习和自主探索能力提供了重要突破。机器人在现实世界中的应用,特别是在操作复杂物体时,往往受到强化学习算法数据需求量大、手动奖励设计繁琐等问题的限制。为了克服这些挑战,团队提出了RLFP框架,通过利用大模型(如策略、价值和成功奖励模型)的先验知识,为强化学习过程提供反馈和指导,从而显著提升了机器人在探索新环境时的效率,并减少了对手动设计奖励函数的依赖。
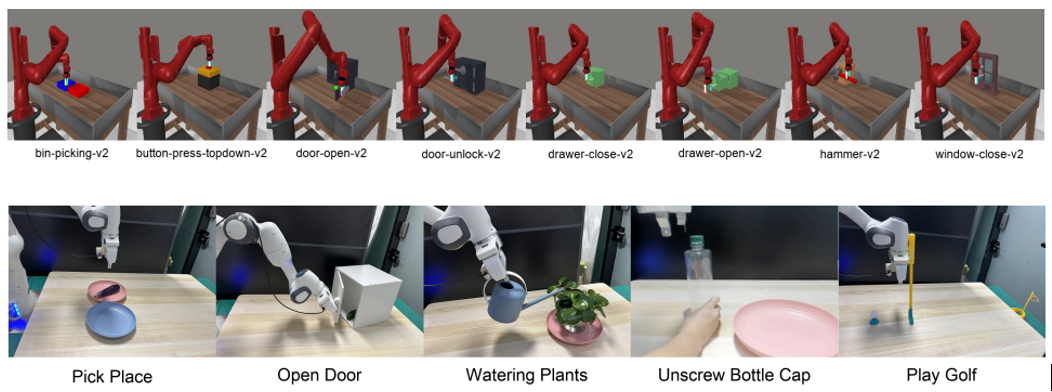
图1. FAC算法的测试环境(含8种模拟场景和5种真实场景)
高阳团队创新性地提出了基础模型引导的Actor-Critic(Foundation-guided Actor-Critic, FAC)算法,旨在自动生成奖励函数,并为机器人提供智能探索路径。该算法通过结合分层强化学习和基础模型的预训练策略,解决了机器人在真实世界中操作任务中常见的样本效率低和手动奖励设计难的问题。

图2. 大模型先验策略知识的失败案例和FAC的成功案例
RLFP框架提出的创新在于通过大模型的先验信息来引导强化学习过程,极大减少了手动工程设计的工作量。FAC算法通过自动生成奖励和引导策略,允许机器人更快适应任务环境,从而减少了传统RL方法中大规模数据采集和繁琐的奖励函数设计。
RLFP框架及FAC算法有效解决了机器人操作任务中数据采集成本高和奖励函数难以设计的问题。传统的强化学习方法往往需要数百万次的环境交互,而RLFP仅需不到1小时的训练时间,便能在仿真和真实环境中取得显著成功。该方法在5个真实机器人任务中的平均成功率达到86%,而在Metaworld模拟器中的8个任务中,RLFP框架在其中7个任务中实现了100%的成功率,大幅超越了基于手动设计奖励的基准方法。
RLFP框架为机器人自主探索和复杂任务操作提供了全新的解决方案,具有重要的实际应用潜力。它不仅加速了强化学习算法在真实世界中的落地,还为未来机器人能够自主学习、应对更多样化任务奠定了基础。该框架对机器人感知能力、底层控制策略及复杂环境中的自适应学习提供了研究新思路,展示了在强化学习与机器人领域的广泛应用前景。
论文信息:Reinforcement Learning with Foundation Priors: Let the Embodied Agent Efficiently Learn on Its Own, Weirui Ye, Yunsheng Zhang, Haoyang Weng, Xianfan Gu, Shengjie Wang, Tong Zhang, Mengchen Wang, Pieter Abbeel, Yang Gao†, https://arxiv.org/pdf/2310.02635, CoRL 2024 ( Oral ).
------------------------------------------------------------------------------------------------------------------------------
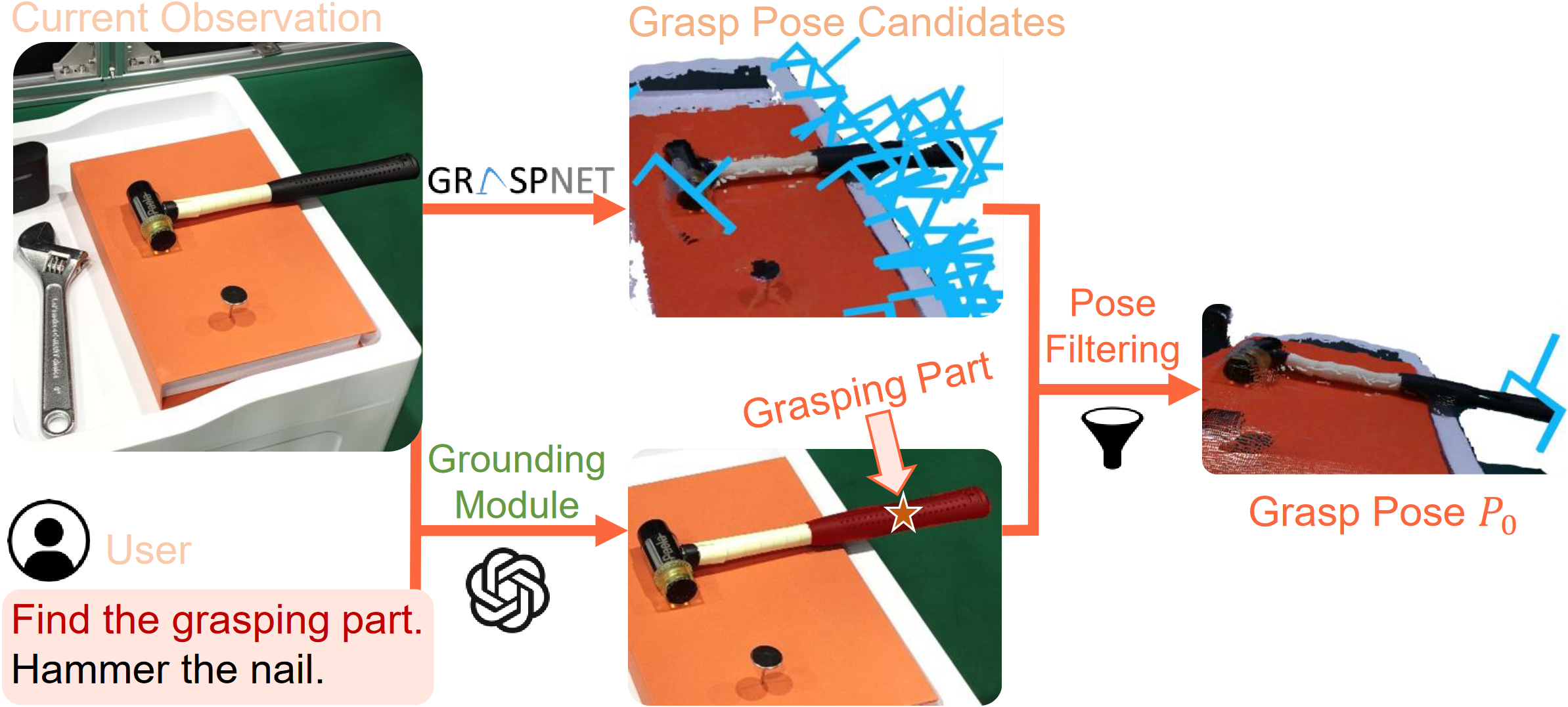
成果6:基于基础大模型生成物体部件间空间约束的机器人通用操作框架—CoPa(2024年度)
在机器人技术领域,适应复杂环境的操作能力是关键挑战之一。然而,操作任务中的每个低层控制指令的实现往往依赖于特定任务上的学习方法或人为定义的规则,因此需要大量的数据收集工作或人力付出,并且难以泛化到不同场景和任务。与此同时,在互联网规模数据上训练得到的基础大模型被证实隐含着对世界的广泛常识知识。研究者发现其在机器人操作的高层任务规划中的应用是十分有效的。而其在低层控制中的应用尚待研究。
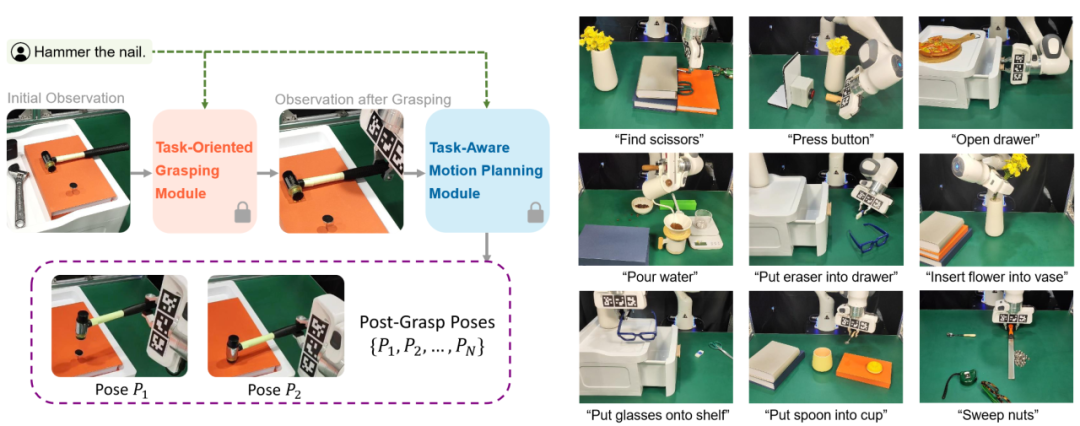
图1. CoPa—利用基础大模型实现机器人通用操作
高阳团队研究了这个问题,提出了“基于物体部位间约束的通用机器人工具操作框架”。此创新框架可以将大模型内嵌的常识运用到低层的机器人控制当中,通过物体部位间约束生成一系列末端执行器六自由度位姿,从而解决开放世界中的任务与物体操作任务,并且无需复杂的提示词设计和额外的训练。此外,该框架还可以与高层任务规划算法无缝衔接,完成如制作手冲咖啡和布置浪漫餐桌等长周期复杂任务。
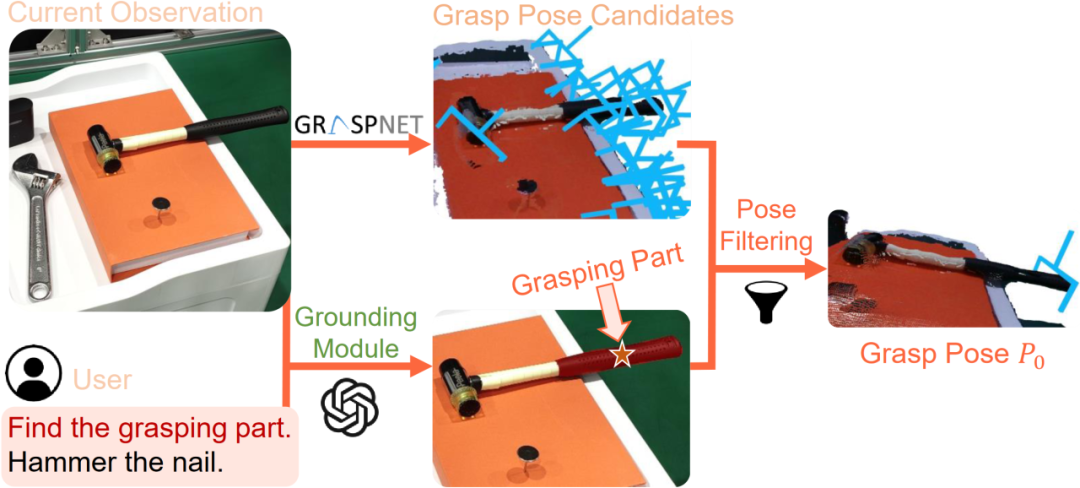
图2. 任务导向抓取阶段示意图

图3. 任务导向运动规划阶段示意图
CoPa将操作任务分成两个阶段:任务导向抓取阶段和抓取后任务导向运动规划阶段。在抓取阶段,抓取物体部位定位模块,利用视觉语言大模型定位待抓取物体部位的掩膜,用以过滤预训练抓取模型生成的候选抓取位姿,得到最终的任务导向抓取位姿。在任务导向运动规划阶段,先使用定位模块定位任务相关的物体部位;然后让视觉语言大模型描述部位间应当满足的空间几何约束;最后使用一个优化问题求解器解得目标位姿序列,使用路径规划算法得到运动轨迹。CoPa使用部位间空间约束作为连接视觉语言大模型和机器人的桥梁,可以很好地利用视觉语言大模型中的知识常识,并且具有精细的物理理解能力,同时又可以利用传统的控制算法,实现精准流畅的操作。
团队在真机实验平台上验证了这个框架的有效性。CoPa在 10 个任务中取得了 63% 的平均成功率,显著高于基准方法 VoxPoser。在消融实验中,通过与 3 个变种的对比,展现了框架中视觉语言大模型、由粗到细的定位设计和空间约束的表示方式的重要性。最后,CoPa还与高层任务规划算法ViLa集成,完成了复杂长周期操作任务。
CoPa为机器人通用操作提出了一种新的可能。
项目论文:CoPa: General Robotic Manipulation through Spatial Constraints of Parts with Foundation Models, Haoxu Huang, Fanqi Lin, Yingdong Hu, Shenjie Wang, Yang Gao†, https://copa-2024.github.io/, IROS 2024.
------------------------------------------------------------------------------------------------------------------------------
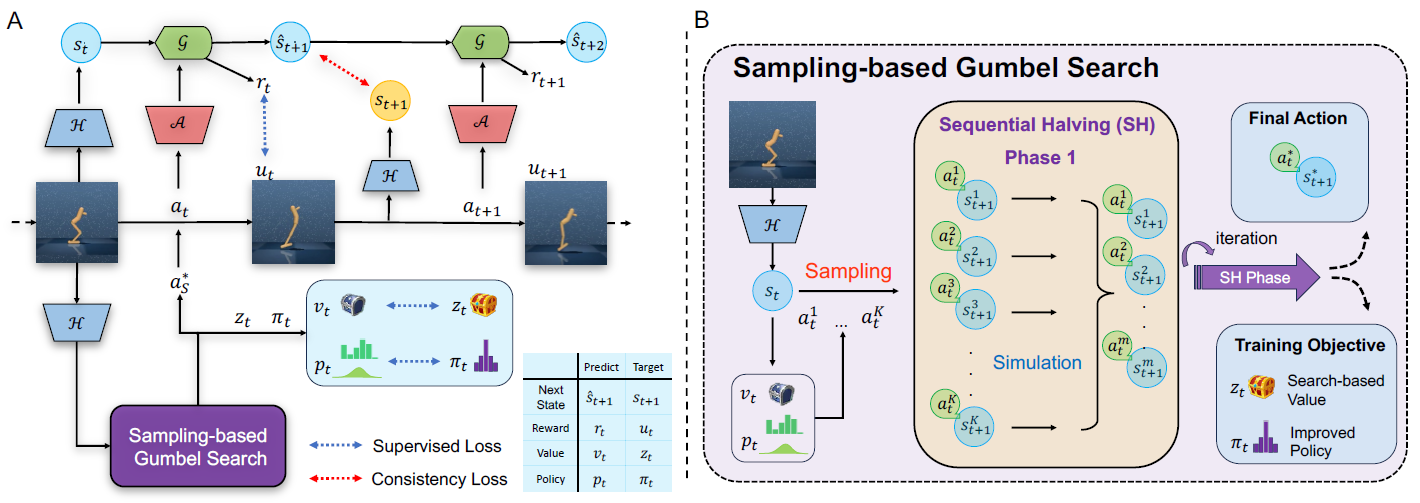
成果5:通用且采样高效的EfficientZero系列强化学习算法(2024年度)
EfficientZero V2
强化学习 (RL) 已经在诸如围棋、电子游戏和机器人控制等多种任务上表现出色。然而,这些算法需要与环境进行大量的交互,导致时间和计算成本显著增加。例如,一个基于RL的控制器需要近100M次交互才能在使用视觉信息作为输入的场景中,正确操作物体完成日常任务。此外,如果考虑用于完成日常家务的机器人,为其构建逼真的模拟器可能是十分困难的工作。而如果在现实世界中收集数据,过程往往既耗时又昂贵。因此,针对RL领域的这个基础性问题,高阳团队提出EfficientZero V2 (EZ-V2) 算法,这是一个专为提升RL算法采样效率而设计的通用框架。该工作将先前团队提出的EfficientZero的性能扩展到了多种领域,包括连续和离散动作,以及视觉和低维状态输入的情况。EZ-V2算法能够以更高的样本效率掌握各个领域的任务。EZ-V2成功将EfficientZero的强大性能扩展到连续控制问题,展示了对多场景的强大适应性。
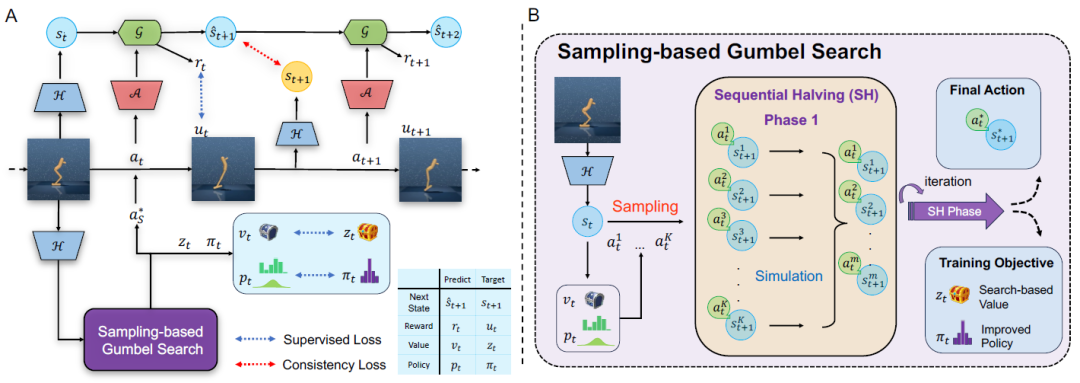
图1. EfficientZero V2框架
本工作的主要贡献如下:
1)提出了一个通用的样本高效强化学习框架。具体来说,该框架在离散和连续控制、视觉和低维状态输入方面均实现了稳定的样本效率。
2)在多个基准测试中评估了提出的方法,EZ-V2的性能优于之前的SOTA算法。在数据预算为50k到200k次交互的情况下,EZ-V2在多个领域的表现大幅超越了此前DeepMind提出的通用算法DreamerV3。
3)算法性能的突破得益于两个重要的算法创新:基于采样的树搜索用于动作规划,确保在连续动作空间中的策略提升;基于搜索的价值估计方法,更加有效地利用先前收集的数据来更新价值函数。
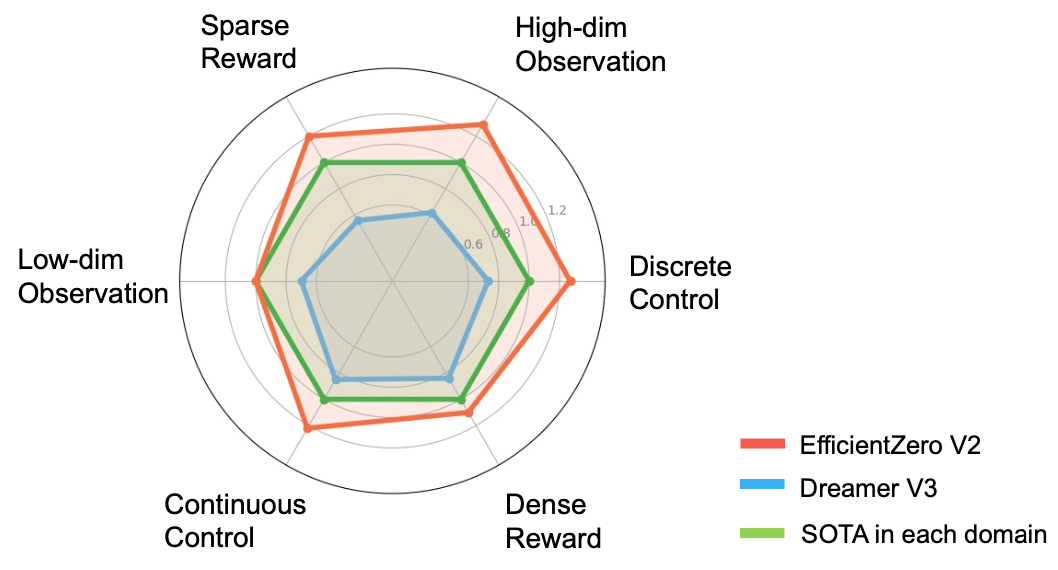
图2. EfficientZero V2和基线算法的对比
EZ-V2算法在各类基准测试中展现出极高的采样效率,对提升现实世界机器人的在线学习具有巨大的潜力。因此团队将继续完善EfficientZero系列算法,在具身智能等场景下实现更广泛的应用。
论文信息:EfficientZero V2: Mastering Discrete and Continuous Control with Limited Data, Shengjie Wang*, Shaohuai Liu*, Weirui Ye*, Jiacheng You, and Yang Gao, https://arxiv.org/abs/2403.00564, ICML 2024.
-------------------------------------------------------------------------------------------------------------------
成果4:VILA算法框架(2024年度)

机器人任务规划领域面临的一大挑战是如何使机器人能够理解复杂的视觉语言信息并据此做出决策。针对此,高阳团队提出了ViLa框架(Robotic Vision-Language Planning)。ViLa的核心创新在于直接使用了视觉语言模型来帮助机器人进行推理,解决了传统大型语言模型缺乏物理世界感知的问题。得益于对GPT-4V视觉语言模型的创新使用,ViLa在对空间布局和物体属性的理解能力上有显著的提升,同时还支持多模态目标设定和视觉反馈,增强了机器人在动态环境中的闭环规划能力。在真实世界和模拟环境中的测试表明,ViLa在多个长周期操作任务上均展现出色的表现,验证了其有效性。
展望未来,ViLa的应用前景广阔。它不仅能提升个人助理机器人的自主性,还能在工业自动化等领域发挥重要作用。随着技术的进一步成熟,ViLa有望成为推动机器人智能化的关键技术之一,为机器人执行复杂任务提供强有力的支持。
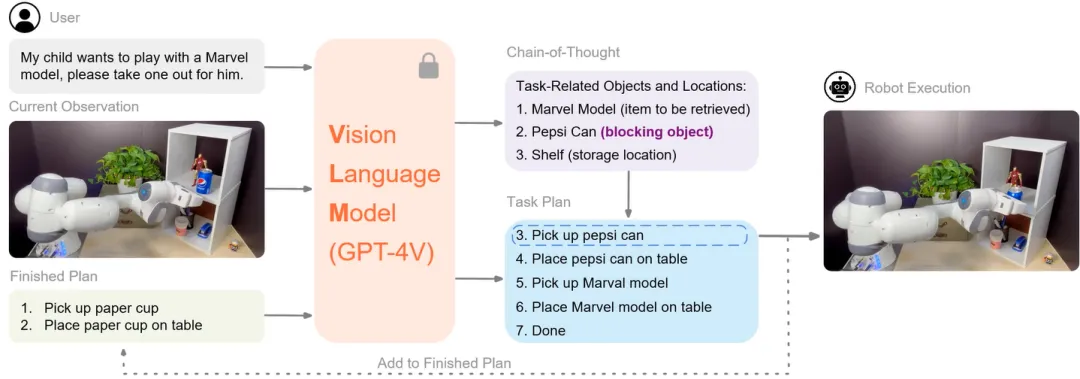
项目论文:Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning,Yingdong Hu*, Fanqi Lin*, Tong Zhang, Li Yi, Yang Gao, ICRA 2024
项目链接:https://robot-vila.github.io/
---------------------------------------------------------------------------------------------------------
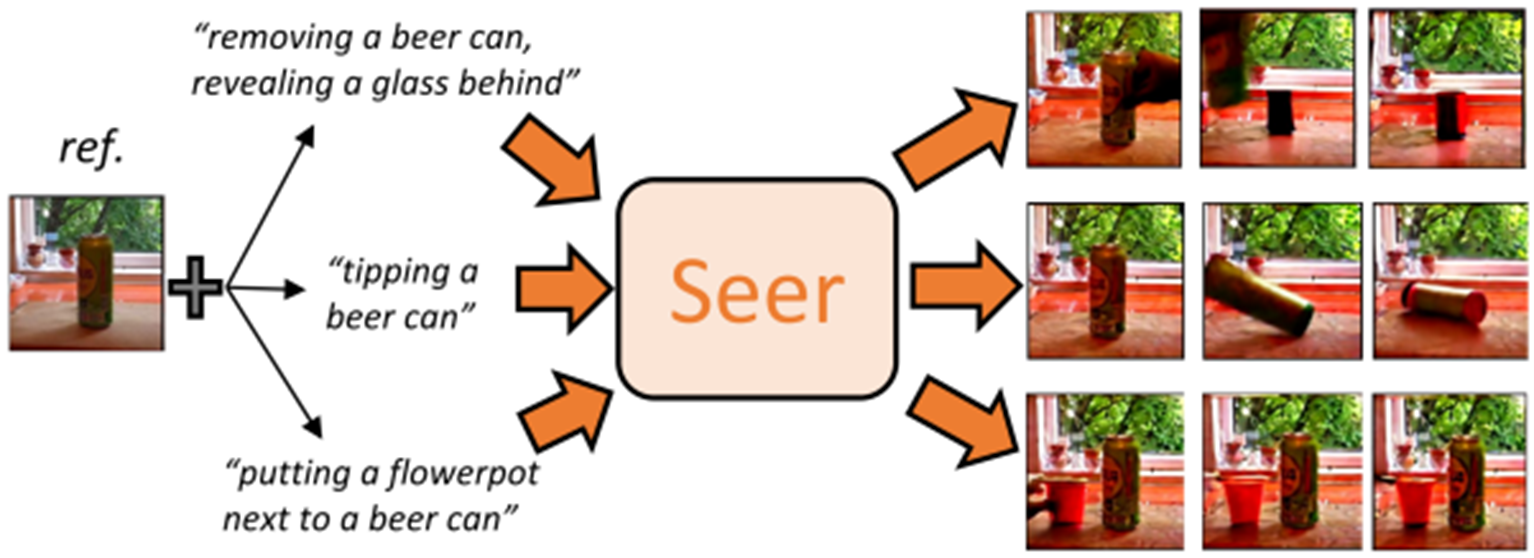
成果3:模仿学习和机器人感知系列算法攻关—Seer & ADS & RelatiViT(2024年度)
通过当前环境观察分析预测并基于先验知识去预想未来的轨迹是机器人做出合理规划并成功实现目标的关键。文本条件视频预测在通用机器人策略学习中扮演关键角色,但其性能受到三大限制:1)需要大规模标记文本视频数据集和昂贵的计算成本;2)生成帧的保真度低:模型生成的帧通常是独立随机的;3)任务级视频中的每一帧缺乏细粒度的指令:这使得仅以全局指令引导连续轨迹并在每个时间步生成相应的帧变得困难。
高阳团队提出的Seer模型通过一系列创新解决了这些问题。通过冻结预训练扩散模型,并结合计算高效的时空注意力和语言条件模型,Seer能够有效地生成高保真、连贯且指令对齐的视频帧。此外,研究人员引入了一种新颖的延帧的时间顺序分解语言指令的分解器模块,该模块将句子的全局指令分解为时间对齐的子指令,确保精确对齐到每个生成帧中。
凭借上述适应性设计的架构,Seer可以通过在少量数据上微调几个层来生成高保真、连贯且指令对齐的视频帧。实验结果表明,该方法在大约 480个 GPU 小时的视频预测性能优于具有超过 12,480 个 GPU 小时的 当前开源视频生成基准模型CogVideo:与当前的最优模型相比,实现了31%的弗雷歇视频距离(FVD)指标的提升,并且人类观察评估中该方法生成结果相比其他基准模型达到更高的83.7%的平均择优率。借助预训练文本图像生成模型和精心设计的架构,Seer实现了高质量视频生成,显著降低了数据和计算成本。
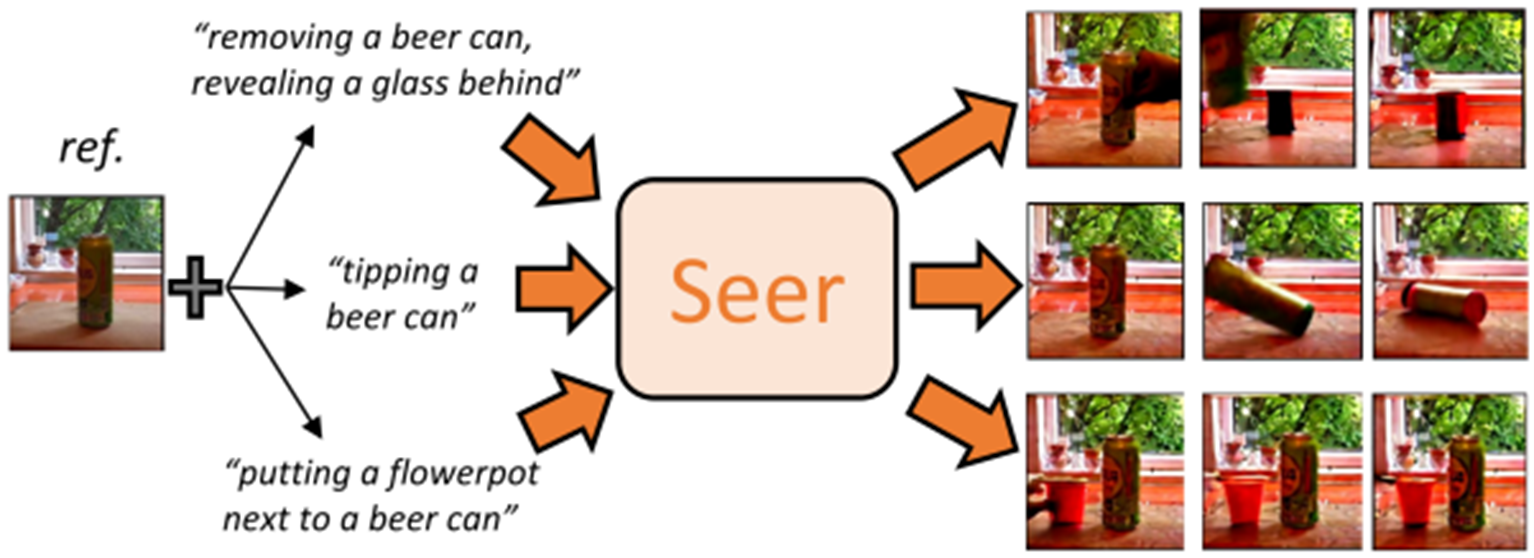
图1. Seer-高效的视频扩散模型
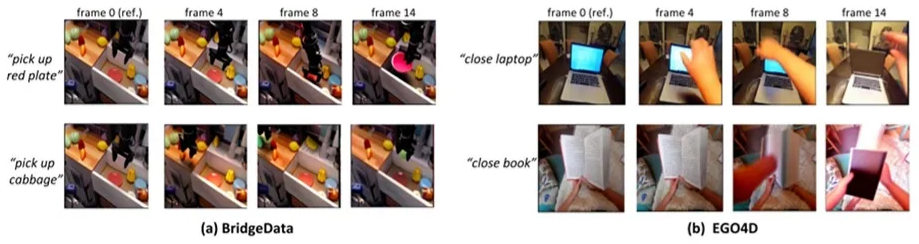
图2.模型在新数据集(EGO4D)和新文本命令的推理泛化(零次生成)结果
-----------------------------------------------------------------------------------------------------------------------
成果2:针对机器人操控的通用“语义-几何表征”(2023年度)
机器人在感知和与世界交互时高度依赖传感器,尤其是RGB摄像头和深度摄像头。RGB摄像头记录了具有丰富语义信息的2D图像,但缺失了精确的空间信息;另一方面,深度摄像头提供了关键的3D几何数据,但捕获的语义信息有限。因此,整合这两种模式对于机器人感知和控制的表征是至关重要的。然而,当前的研究主要集中在其中一种模式上,忽视了结合两者的好处。
为了解决这个问题,高阳团队提出了“语义-几何表征”(Semantic-Geometric Representation, SGR),这是一个针对机器人的通用感知模块,它不仅充分利用了大规模预训练2D模型中的丰富语义信息,还结合了3D空间的推理优势。我们的实验结果显示,“语义-几何表征”使机器人能够出色地应对各类仿真与实际场景中的任务,无论是单任务还是多任务情境,其表现都超过之前最先进的方法。值得一提的是,“语义-几何表征”在处理新的语义属性上展现了出色的泛化能力,这一特性也使其显著区别于其他技术。
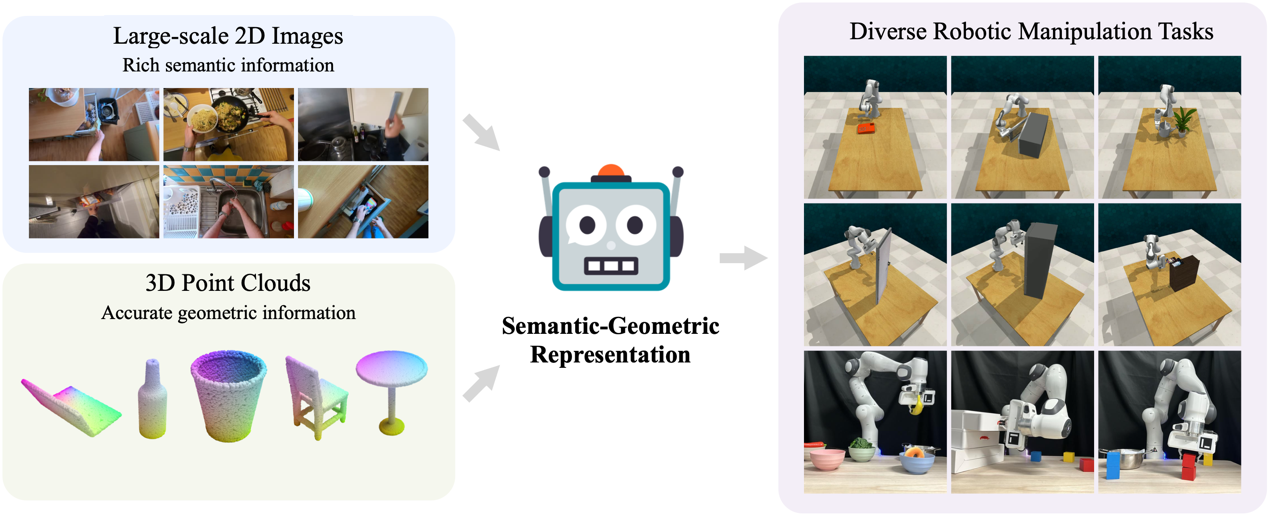
研究领域:机器人的视觉表征
项目网站: https://semantic-geometric-representation.github.io/
研究论文: Zhang, Tong, Yingdong Hu, Hanchen Cui, Hang Zhao, and Yang Gao. ‘A Universal Semantic-Geometric Representation for Robotic Manipulation’. In Conference on Robot Learning (CoRL), 2023. 查看PDF
------------------------------------------------------------------------------------------------------------------------------
成果1: 高效率强化学习(2022年度)
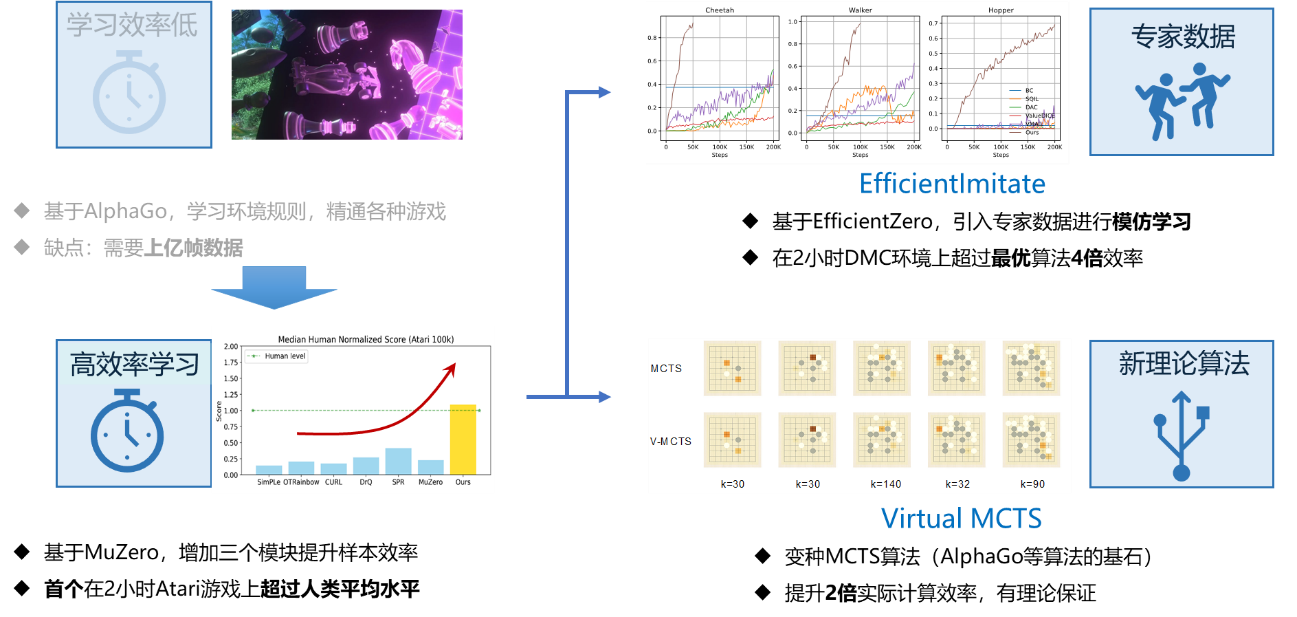
强化学习被认为是实现通用人工智能的重要路线之一。但强化学习往往需要海量的数据,难以在物理世界中应用。高阳团队提出一种新型强化学习算法EfficientZero,可仅用少量数据情况下取得高性能。团队针对蒙特卡洛强化学习算法的训练信号弱、模型累计误差和无法有效利用离线数据的三大问题,提出了系统化解决方法。提出了时序自监督学习、前缀值函数拟合和自适应值函数修正等算法创新,最终在仅使用2小时真实世界数据情况下,在Atari基准测试上达到了人类性能的109%。这是强化学习算法首次在有限数据情况下达到超越人类的能力。该算法的样本效率首次超越了人类的水平,达到了谷歌提出的经典强化学习算法DQN数据效率的近600倍。EfficientZero算法解决了强化学习领域的重大基础科学问题,填补了国际高效率强化学习领域的空白,为强化学习的物理世界落地铺平了道路。
在EfficientZero之上,为了更加容易地在物理世界使用强化学习算法,高阳团队开发了EfficientImitate算法,可以在不使用奖励函数情况下进行高效率学习;同时也开发了Virtual MCTS大幅度提升EfficientZero的计算效率。
41. KineDex: Learning Tactile-Informed Visuomotor Policies via Kinesthetic Teaching for Dexterous Manipulation, Di Zhang*, Chengbo Yuan, Chuan Wen, Hai Zhang, Junqiao Zhao, Yang Gao†,CoRL 2025.
40. HuB: Learning Extreme Humanoid Balance, Tong Zhang*, Boyuan Zheng*, Ruiqian Nai, Yingdong Hu, Yen-Jen Wang, Geng Chen, Fanqi Lin, Jiongye Li, Chuye Hong, Koushil Sreenath, Yang Gao†,CoRL 2025.
39. RoboEngine: Plug-and-Play Robot Data Augmentation with Semantic Robot Segmentation and Background Generation, Chengbo Yuan*, Suraj Joshi*, Shaoting Zhu*, Hang Su, Hang Zhao, Yang Gao†,IROS 2025.
38. Learning Manipulation Skills through Robot Chain-of-Thought with Sparse Failure Guidance, Kaifeng Zhang, Zhao-Heng Yin, Weirui Ye, Yang Gao†,IROS 2025.
37. Self-Supervised Monocular 4D Scene Reconstruction for Egocentric Videos, Chengbo Yuan, Geng Chen, Li Yi, Yang Gao†,ICCV 2025
36. Leveraging Locality to Boost Sample Efficiency in Robotic Manipulation, Tong Zhang, Yingdong Hu, Jiacheng You, Yang Gao†, https://sgrv2-robot.github.io/, CoRL 2024.
35. General Flow as Foundation Affordance for Scalable Robot Learning, Chengbo Yuan, Chuan Wen, Tong Zhang, Yang Gao†, https://general-flow.github.io/, CoRL 2024.
34. DexCatch: Learning to Catch Arbitrary Objects with Dexterous Hands, Fengbo Lan*, Shengjie Wang*, Yunzhe Zhang, Haotian Xu, Oluwatosin Oseni, Yang Gao†, Tao Zhang†, https://dexcatch.github.io/, CoRL 2024.
33. Reinforcement Learning with Foundation Priors: Let the Embodied Agent Efficiently Learn on Its Own, Weirui Ye, Yunsheng Zhang, Haoyang Weng, Xianfan Gu, Shengjie Wang, Tong Zhang, Mengchen Wang, Pieter Abbeel, Yang Gao†, https://arxiv.org/pdf/2310.02635, CoRL 2024 ( Oral ).
32. MQE: Unleashing the Power of Interaction with Multi-agent Quadruped Environment, Ziyan Xiong, Bo Chen, Shiyu Huang, Wei-wei Tu, Zhaofeng He, Yang Gao†, https://ziyanx02.github.io/multiagent-quadruped-environment/, IROS 2024.
31. CoPa: General Robotic Manipulation through Spatial Constraints of Parts with Foundation Models, Haoxu Huang, Fanqi Lin, Yingdong Hu, Shenjie Wang, Yang Gao†, https://copa-2024.github.io/, IROS 2024.
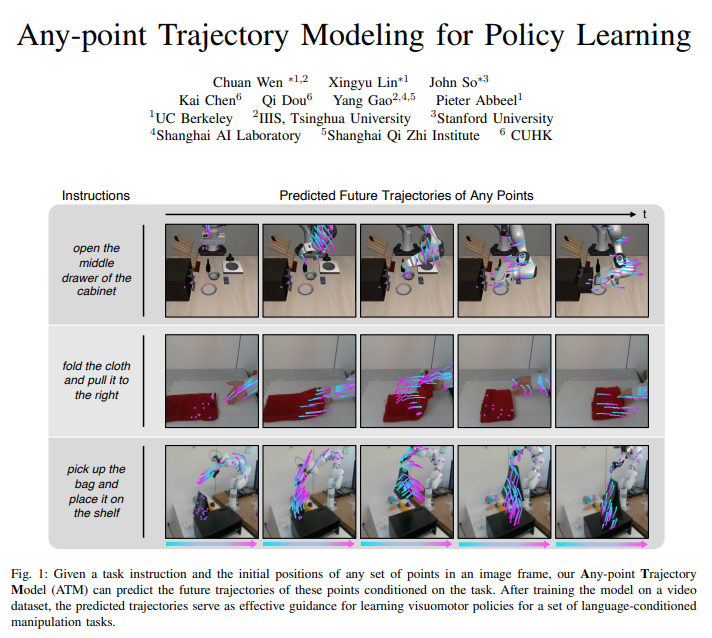
30. Any-point Trajectory Modeling for Policy Learning, Chuan Wen, Xingyu Lin, John So, Kai Chen, Qi Dou, Yang Gao, RSS 2024.
29. EfficientZero V2: Mastering Discrete and Continuous Control with Limited Data, Shengjie Wang*, Shaohuai Liu*, Weirui Ye*, Jiacheng You, and Yang Gao, https://arxiv.org/abs/2403.00564, ICML 2024.
28. Yingdong Hu*, Fanqi Lin*, Tong Zhang, Li Yi, Yang Gao, Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning, ICRA 2024
27. Haoxu Huang*, Fanqi Lin*, Yangdong Hu, Shenjie Wang, Yang Gao., CoPa: General Robotic Manipulation through Spatial Constraints of Parts with Foundation Models, ICRA 2024
26. Yuyang Liu*, Weijun Dong*, Yingdong Hu, Chuan Wen, Zhao-Heng Yin, Chongjie Zhang, Yang Gao, Imitation Learning from Observation with Automatic Discount Scheduling. ICLR 2024
25. Chuan Wen, Dinesh Jayaraman, Yang Gao, Can Transformers Capture Spatial Relations between Objects?, ICLR 2024
24. Xianfan Gu, Chuan Wen, Weirui Ye, Jiaming Song, Yang Gao, Seer: Language Instructed Video Prediction with Latent Diffusion Models, ICLR 2024
23. Kaifeng Zhang, Rui Zhao, Ziming Zhang, Yang Gao, Auto-Encoding Adversarial Imitation Learning, International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2023 查看PDF
22. Tong Zhang, Yingdong Hu, Hanchen Cui, Hang Zhao, Yang Gao, A Universal Semantic-Geometric Representation for Robotic Manipulation, International Conference on Robots Learning (CORL), 2023 查看PDF
21. Shengjie Wang, Fengbo Lan, Xiang Zheng, Yuxue Cao, Oluwatosin Oseni, Haotian Xu, Tao Zhang, Yang Gao, A Policy Optimization Method Towards Optimal-time Stability, International Conference on Robots Learning (CORL), 2023 查看PDF
20. Jialei Huang, Zhaoheng Yin, Yingdong Hu, Yang Gao, Policy Contrastive Imitation Learning, International Conference on Machine Learning (ICML), 2023 查看PDF
19. Yingdong Hu, Renhao Wang, Li Erran Li, Yang Gao, For Pre-Trained Vision Models in Motor Control, Not All Policy Learning Methods are Created Equal, International Conference on Machine Learning (ICML), 2023 查看PDF
18. Kaizhe Hu, Ray Chen Zheng, Yang Gao, Huazhe Xu, Decision Transformer under Random Frame Dropping, International Conference on Learning Representation (ICLR), 2023 查看PDF
17. Zhengrong Xue, Zhecheng Yuan, Jiashun Wang, Xueqian Wang, Yang Gao, Huazhe Xu, USEEK: Unsupervised SE(3)-Equivariant 3D Keypoints for Generalizable Manipulation, International Conference on Robot Automation (ICRA), 2023 查看PDF
16. Yixuan Mei, Jiaxuan Gao, Weirui Ye, Shaohuai Liu, Yang Gao, Yi Wu, SpeedyZero: Mastering Atari with Limited Data and Time, International Conference on Learning Representation (ICLR), 2023 查看PDF
15. Jiaye Teng, Chuan Wen, Dinghuai Zhang, Yoshua Bengio, Yang Gao, Yang Yuan, Predictive Inference with Feature Conformal Prediction, International Conference on Learning Representation (ICLR), 2023 查看PDF
14. Weirui Ye, Yunsheng Zhang, Pieter Abbeel, Yang Gao, Become a Proficient Player with Limited Data through Watching Pure Videos, International Conference on Learning Representation (ICLR), 2023 查看PDF
13. Renhao Wang, Jiayuan Mao, Joy Hsu, Hang Zhao, Jiajun Wu, Yang Gao, Programmatically Grounded, Compositionally Generalizable Robotic Manipulation, International Conference on Learning Representation (ICLR), 2023 查看PDF
12. Chuan Wen, Jianing Qian, Jierui Lin, Jiaye Teng, Dinesh Jayaraman, Yang Gao, Fighting Fire with Fire: Avoiding DNN Shortcuts through Priming, International Conference on Machine Learning (ICML), 2022 查看PDF
11. Zhecheng Yuan, Zhengrong Xue, Bo Yuan, Xueqian Wang, Yi Wu, Yang Gao, Huazhe Xu, Pre-Trained Image Encoder for Generalizable Visual Reinforcement Learning, Conference on Neural Information Processing Systems (NeurIPS), 2022 查看PDF
10. Jinkun Cao, Ruiqian Nai, Qing Yang, Jialei Huang, Yang Gao, An Empirical Study on Disentanglement of Negative-free Contrastive Learning, Neural Information Processing Systems (NeurIPS), 2022 查看PDF
9. Zhao-Heng Yin, Weirui Ye, Qifeng Chen, Yang Gao, Planning for Sample Efficient Imitation Learning, Neural Information Processing Systems (NeurIPS), 2022 查看PDF
8. Weirui Ye, Pieter Abbeel, Yang Gao, Spending Thinking Time Wisely: Accelerating MCTS with Virtual Expansions, Neural Information Processing Systems (NeurIPS), 2022 查看PDF
7. Renhao Wang, Hang Zhao, Yang Gao, CYBORGS: Contrastively Bootstrapping Object Representations by Grounding in Segmentation, European Conference on Computer Vision (ECCV), 2022 查看PDF
6. Yingdong Hu, Renhao Wang, Kaifeng Zhang, Yang Gao, Semantic-Aware Fine-Grained Correspondence, European Conference on Computer Vision (ECCV), 2022 查看PDF
5. Chia-Chi Chuang, Donglin Yang, Chuan Wen, Yang Gao, Resolving Copycat Problems in Visual Imitation Learning via Residual Action Prediction, European Conference on Computer Vision (ECCV), 2022 查看PDF
4. Chenyu Yang, Wanrong He, Yingqing Xu, and Yang Gao, EleGANt: Exquisite and Locally Editable GAN for Makeup Transfer, European Conference on Computer Vision (ECCV), 2022 查看PDF
3. Chuan Wen*, Jierui Lin*, Jianing Qian, Yang Gao, Dinesh Jayaraman, Keyframe-Focused Visual Imitation Learning. International Conference on Machine Learning (ICML) , 2021 查看PDF
2. Weirui Ye, Shaohuai Liu, Thanard Kurutach, Pieter Abbeel, Yang Gao, Mastering Atari Games with Limited Data Advances, Neural Information Processing Systems (NeurIPS), 2021 查看PDF
1. Chuan Wen*, Jierui Lin*, Trevor Darrell, Dinesh Jayaraman, Yang Gao, Fighting Copycat Agents in Behavioral Cloning from Observation Histories, Neural Information Processing Systems (NeurIPS), 2020 查看PDF