成果7:基于联合扩散去噪过程的视觉策略学习—PAD(2024年度)
近期,扩散生成模型在图像、视频生成取得了巨大的成功,展现出了对物理世界的良好理解。同时,扩散策略(diffusion policy)也在机器人任务中取得了巨大的成功。使用扩散视频生成模型来帮助构建机器人基础模型是一条有前景的道路。陈建宇团队发现,扩散生成模型和扩散策列在技术上都采用同样的去噪过程,因此提出使用联合去噪策略学习模型PAD,将未来图像生成和动作生成融合到一个网络中,从而让视频预测能力帮助机器人学习。
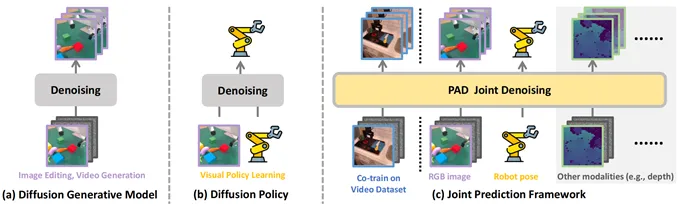
图1. PAD将扩散生成模型和扩散策略融合到同一网络
陈建宇团队使用多层Diffusion Transformer(DiT)结构来简洁地完成联合预测任务。RGB观测、机器人位姿、深度等各种模态数据被映射到相同的空间中,通过简单的输入令牌拼接(token)和注意力遮盖机制(attention-mask),机器人数据可以与动作缺失的视频数据进行联合训练。
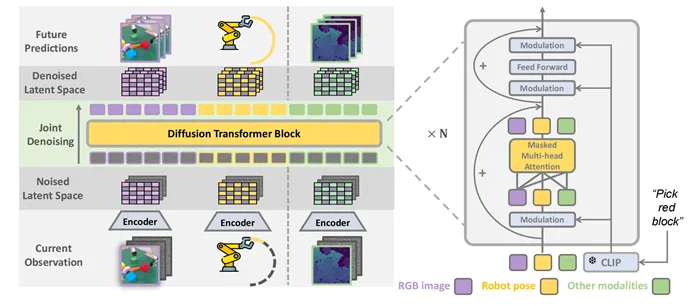
图2. PAD输入当前RGB图,机器人位置,深度图,进行联合去噪过程
在实验中,团队在仿真的metaworld机械臂环境和真实Panda机械臂环境中进行了大量实验。团队使用一个视觉语言输入的策略解决了metaworld环境中的所有50个任务,获得了相对于基线算法26%的提升。在真实世界任务中,在未知任务也获得了28%的成功率提升。同时团队发现,PAD模型呈现出良好的scaling性质,可以通过提升训练模型的计算量来提升策略性能。

图3. 仿真环境、真实环境的性能对比图,Scaling实验图
PAD有潜力发展为基于视频生成的通用机器人基础模型。本论文共同第一作者为上海期智研究院实习生、清华大学博士生郭彦江、胡钰承,通讯作者为上海期智研究院PI、清华大学助理教授陈建宇。共同作者为上海期智研究院实习生、清华大学博士生张荐科、陈晓宇、王彦仁,上海人工智能实验室陆超超。
论文信息:Prediction with Action: Visual Policy Learning via Joint Denoising Process, Yanjiang Guo∗, Yucheng Hu*, Jianke Zhang, Yen-Jen Wang, Xiaoyu Chen, Chaochao Lu, Jianyu Chen†, https://sites.google.com/view/pad-paper, NeurIPS 2024.
------------------------------------------------------------------------------------------------------------------------------
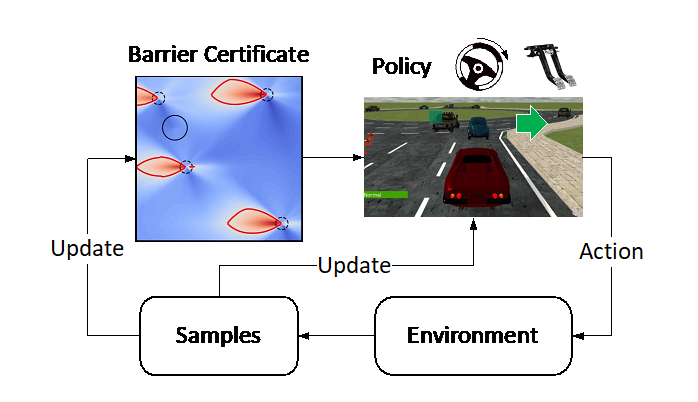
成果6:基于分层机器人变压器的机器人操作控制框架:HiRT(2024年度)
大型视觉语言模型(VLM)虽然在机器人控制中展现了巨大的潜力,但由于大模型计算成本高、推理速度较慢,可能导致机器人动作延迟,执行速度慢或在动态跟随任务上表现较差。
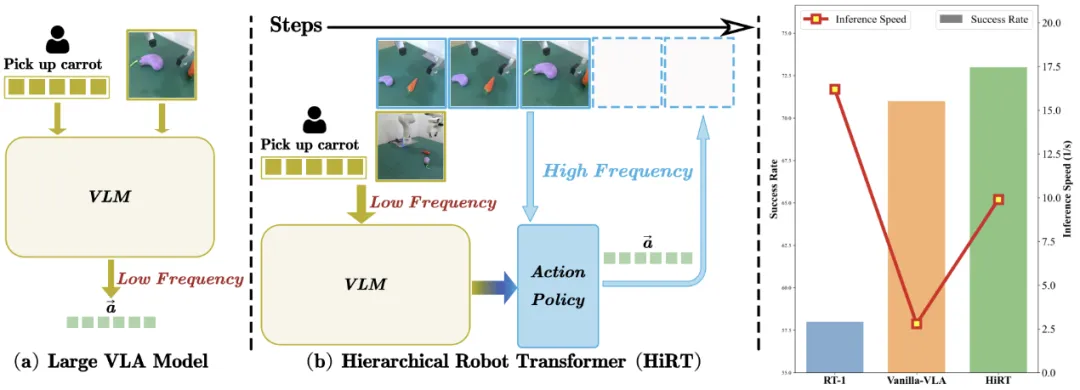
图1. HiRT通过层次化变压器模型来解决大模型推理慢的问题
陈建宇团队探究了这个问题,提出了一种新的层次化模型框架来解决具身多模态大模型推理慢的问题。团队创新地使用该框架将高频的视觉控制策略与低频的大型视觉语言模型(VLM)解耦,前者负责通过视觉信息快速与环境交互,后者则负责提供长期的场景理解与指导。为了能够兼顾模型的泛化性能和推理速度,团队提出了新的条件化策略,使上层的快速交互模型能够异步地使用VLM提供的具有广泛语义信息的表征,使模型能够快速地输出机器人动作并具有较强的语义泛化能力。
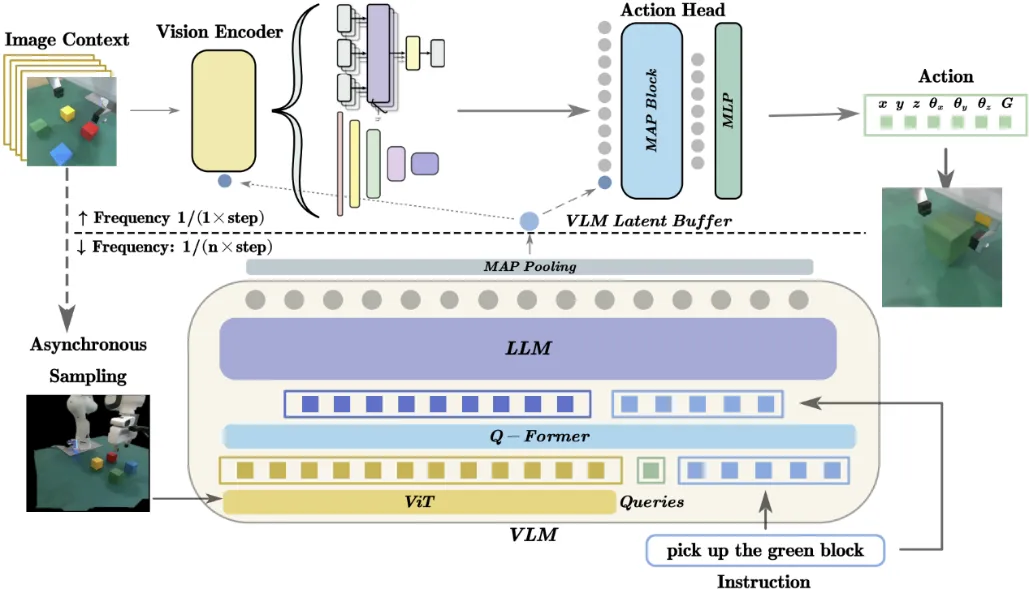
图2. HiRT使小型策略模型与大模型异步执行,兼顾泛化能力和推理效率
在实验中,团队在仿真的机械臂环境和真实场景的机械臂环境中进行了大量实验。在静态操作类任务中,新的方法展示出了模型具有很好的泛化能力,例如模型能够抓取训练数据中未涉及的新物体,并且能够通过调整异步频率平衡模型推理速度的性能,实现兼顾大模型泛化能力和小模型快速推理的目标。同时在真机环境中的动态任务上,新方法具有相比于基线方法更高的成功率和完成速度,例如可以更快地跟随移动的目标物体,这体现出提升具身模型的推理速度能够使机器人更好地在动态场景中执行任务。
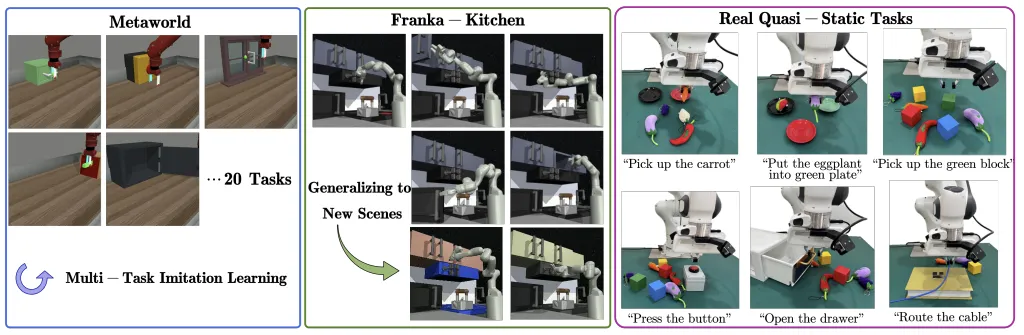
图3. 实验环境:仿真机械臂、真机机械臂硬件平台(静态任务和动态任务)
HiRT有潜力发展为通用的基于视觉语言端到端具身模型框架。本论文共同第一作者为清华大学博士生张荐科,上海期智研究院实习生、清华大学博士生郭彦江,通讯作者为清华大学助理教授陈建宇。
论文信息:HiRT: Enhancing Robotic Control with Hierarchical Robot Transformers, Jianke Zhang∗, Yanjiang Guo∗, Xiaoyu Chen,Yen-Jen Wang, Yucheng Hu, Chengming Shi, Jianyu Chen†, https://arxiv.org/abs/2410.05273, CoRL 2024.
------------------------------------------------------------------------------------------------------------------------------
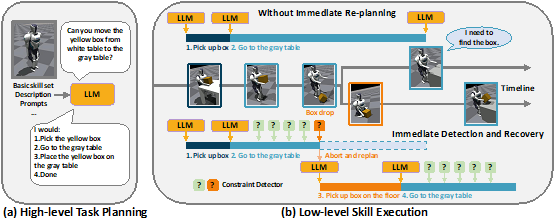
成果5:基于检测和恢复的大语言模型规划框架—DoReMi(2024年度)
大语言模型涌现出对物理世界的认知和推理能力,非常适合帮助机器人完成上层规划。但是由于环境扰动和不完美的控制器,机器人的下层执行策略可能偏移语言模型的上层规划。
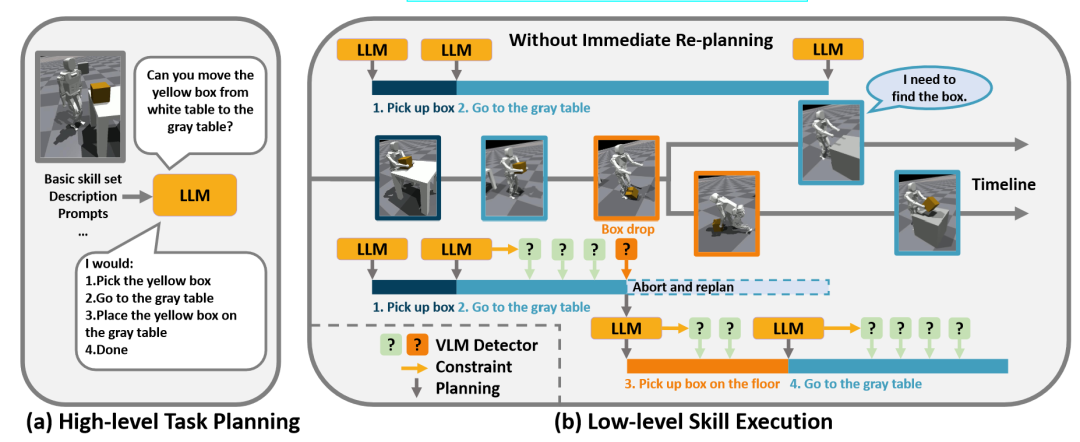
图1. DoReMi框架概览
陈建宇团队探究了这个问题,提出一种新颖的框架来解决上层规划和执行不对齐的问题。基于语言模型的推理能力,在产生规划的同时,也让语言模型输出规划的约束。为了自动化地检测这些约束,团队使用视觉语言大模型统一地检测各种约束。同时为了让视觉语言模型更好适配不同机器人型号,团队使用少量数据对视觉语言模型进行微调,使得其回答更加准确。
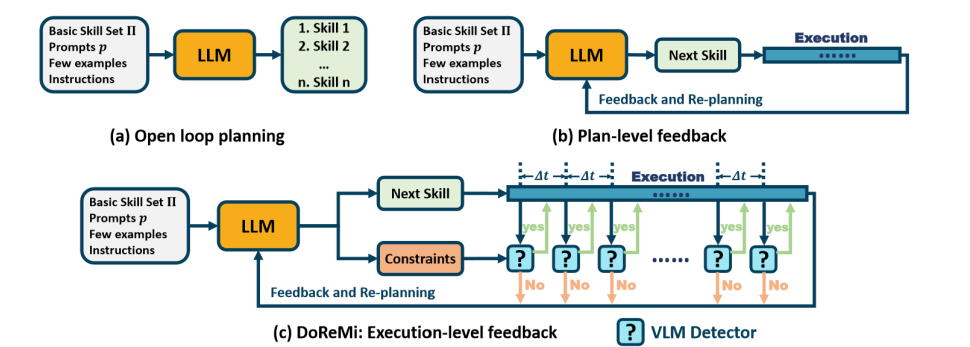
图2. DoReMi使用LLM产生规划和约束,并用微调的视觉语言模型检测异常
DoReMi有潜力发展为通用的规划-执行框架。本论文共同第一作者包括上海期智研究院实习生、清华大学博士生郭彦江,上海期智研究院实习生、清华大学硕士生王彦仁(现加州伯克利大学博士生),清华大学本科生查理涵(现普林斯顿大学博士生),通讯作者为陈建宇助理教授。

图3. 丰富的实验环境:仿真机械臂、仿真人型环境,小星人型机器人硬件平台
DoReMi有潜力发展为通用的规划-执行框架。本论文共同第一作者包括上海期智研究院实习生、清华大学博士生郭彦江,上海期智研究院实习生、清华大学硕士生王彦仁(现加州伯克利大学博士生),清华大学本科生查理涵(现普林斯顿大学博士生),通讯作者为陈建宇助理教授。
项目论文:DoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment, Yanjiang Guo*, Yen-Jen Wang*, Lihan Zha*, Jianyu Chen †, https://sites.google.com/view/doremi-paper, IROS 2024.
------------------------------------------------------------------------------------------------------------------------------
成果4:新颖人形机器人学习算法框架(2024年度)
现代环境设计主要围绕人类需求和能力,因此,具有类似人类骨骼结构的人形机器人特别适合在这种环境中作业。这类机器人在执行任务时展现出显著优势,尤其是在移动性方面。在复杂地形中的行走尤显其重要性。传统上,人形机器人步态的发展极大地依赖于模型控制技术,如零力矩点 (ZMP)、模型预测控制 (MPC)和全身控制 (WBC),这些技术推动了机器人在行走、跳跃乃至后空翻等动作上的进步。然而,这些方法的效果往往受限于对环境动力学的精确建模,特别是在环境交互复杂的场景中,如穿越难行地形,控制复杂度增加。

图1:陈建宇助理教授研究组提出方法在真实世界的实验展示
与此相对,强化学习 (RL) 对环境建模的需求较低。近期在无模型RL领域的进展,显示了在创建普适性腿部运动控制器方面的巨大潜力。此方法使机器人能从多样环境中学习并适应,其性能常超过传统的基于模型的控制方法。尽管如此,与四足和双足机器人相比,实现鲁棒的人形机器人运动控制仍然具有巨大挑战。这些挑战包括但不限于较高的重心、摆动腿时的不稳定性、增加的腿部惯性、来自躯干和手臂的额外重量,以及通常更大的尺寸。目前,将RL应用于人形机器人在现实世界中的控制,研究仍局限于相对简单的地形。
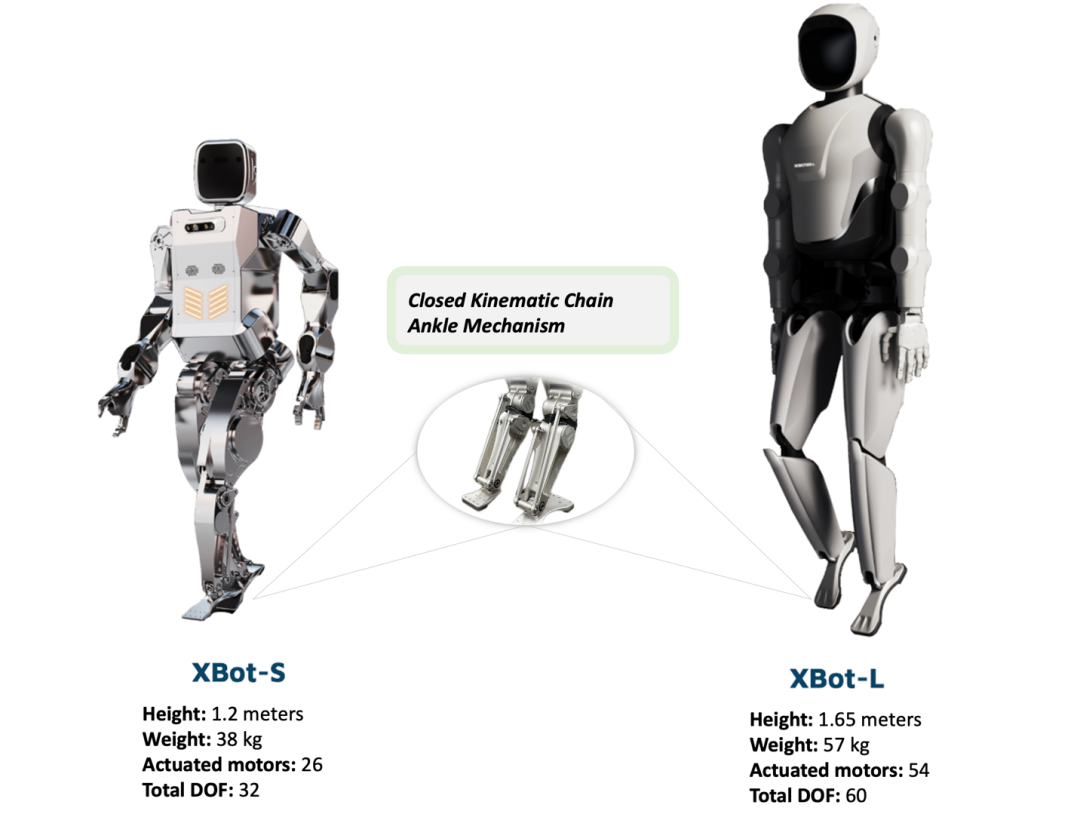
图2:该工作所采用的人形机器人,分别为星动纪元的小星(XBot-S)及小星max(XBot-L)
为应对人形机器人控制领域的挑战,陈建宇助理教授的研究团队在之前开发的Humanoid-Gym平台基础上,进一步提出了去噪世界模型学习 (DWL) 技术,旨在优化人形机器人穿越多样化和复杂地形的能力。该技术已在星动纪元两种尺寸的人形机器人——小星 (XBot-S) 及小星max (XBot-L) 上进行了验证。DWL在全球范围内首次通过端到端RL和零样本仿真到真实转换,实现人形机器人通用适应各类复杂的现实世界地形。如图1所示,人形机器人能够在包括雪地倾斜面、楼梯和不规则表面等各种地形上稳定行走,同时抵抗重大外部干扰。在所有场景中,研究组使用的是同一个神经网络策略,展示了其鲁棒性和泛化能力。DWL的成功主要归功于其创新的表示学习框架,通过有效去噪,极大地缩小了仿真与现实之间的差距。此外,研究组还提出了一个主动2-自由度踝关节(闭环运动链踝机制)的控制方法,如图2所示,显著增强了机器人的鲁棒性。该工作获得了全体审稿人满分评价。
项目论文:Advancing Humanoid Locomotion: Mastering Challenging Terrains with Denoising World Model Learning, Xinyang Gu, Yen-Jen Wang, Xiang Zhu, Chengming Shi, Yanjiang Guo, Yichen Liu, Jianyu Chen, RSS 2024.
------------------------------------------------------------------------------------------------------------------------------
成果3:去中心化的复杂机器人控制算法—DEMOS(2024年度)
人形机器人的全身控制是一个具有挑战性的课题。陈建宇团队提出一种去中心化的复杂机器人控制算法DEMOS,在不牺牲任务性能的前提下,鼓励机器人在强化学习过程中自主发现可以解耦合的模块,同时保留必要合作模块之间的连接。该算法为机器人的设计和开发提供了新的视角,特别是在需要高度自主性和适应性的领域,如搜索和救援、探索和工业自动化。
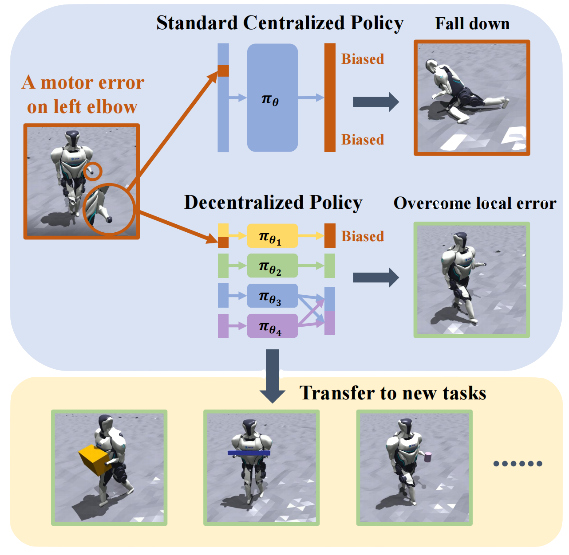
强化学习在足式机器人控制上取得了重大的成功,但是强化学习得到的策略往往是中心化的特异性策略,该策略对局部错误不鲁棒,并且难以迁移到新任务中。陈建宇课题组提出一种去中心化的复杂机器人控制算法DEMOS (Decentralized motor skill),在不牺牲任务性能的前提下,鼓励机器人在强化学习过程中自主发现可以解耦合的模块,同时保留必要合作模块之间的连接。
DEMOS策略在提高机器人系统的鲁棒性、泛化能力和多任务学习方面具有显著的优点,具体包括:
• 对局部错误更加鲁棒,可以克服局部电机故障带来的影响,并且能够更好地泛化到新任务。
• 可以通过组合、微调的方式快速学习新的技能。该方法在四足机器人,机械臂+四足机器人,人型机器人等复杂机器人系统上都展现了优越的性能。
• 该算法为机器人的设计和开发提供了新的视角,特别是在需要高度自主性和适应性的领域,如搜索和救援、探索和工业自动化。
项目论文:Decentralized Motor Skill Learning for Complex Robotic Systems, Yanjiang Guo, Zheyuan Jiang, Yen-Jen Wang, Jingyue Gao, Jianyu Chen, ICRA 2024
------------------------------------------------------------------------------------------------------------------------------
成果2:人形通用智能机器人(2023年度)
构建像人一样的智能机器人是人类一直以来的梦想。人形机器人在软硬件方面都是所有机器人中集成度最高,最复杂的。它能去到所有人能去的地方,干所有人能干的事。由于其完美适用于人类环境,人形机器人是通用人工智能的最佳载体,也具备极其广阔的市场空间。陈建宇团队致力于构建人形通用智能机器人,包括通用本体及其通用智能。通用本体方面,团队研发了基于本体感知驱动器的高性能、低成本人形机器人硬件本体“小星”机器人,搭配具备高扭矩密度电机以及低减速比减速器的一体化关节模组。运动控制算法上,“小星”在全球范围内首次实现了人形机器人端到端强化学习野外雪地行走,包括雪地上下坡,以及上下楼梯。该过程不需要依赖于预先编程的行走模式,而是完全通过AI自主学习实现的。这使得机器人能够自主地适应不同的地面条件,从而在复杂的雪地环境中稳定行走。


在具身智能方面,团队提出了DoReMi框架,这是世界第一篇用大语言模型赋能人形机器人决策的文章。该工作改进了上层语言模型规划与下层强化学习策略的对齐问题,将视觉语言模型、大语言模型与人形机器人算法进行整合,用大型语言模型指导小星的上层任务规划,用强化学习来获取小星的底层控制器,构成的框架可以增强其执行任务的智能性和泛化性。
------------------------------------------------------------------------------------------------------------------------------
成果1:安全强化学习(2022年度)
强化学习对解决复杂的机器人问题具有巨大的前景,包括自动驾驶、机械臂操作等。然而将强化学习应用于上述实体机器人系统上时却有很大的安全隐患。无论是训练过程中还是训练收敛后,基于神经网络的机器人控制策略都可能出现问题并造成与环境之间的危险碰撞。
陈建宇团队首先从强化学习的约束保障出发,基于控制理论中的前向不变性,提出了针对机器人动力系统的通用安全保障机制,以及耦合该机制的强化学习框架。在理论允许的范围中,该方法能保障系统的安全性,并在实际算法验证中得到零安全约束违反的结果。同时,针对约束无法避免的情况,团队通过整合冗余自由度机械臂的零空间控制、变阻抗控制、以及基于视觉的强化学习等理论与算法,提出了一套保障接触安全的强化学习框架。该框架能不仅能保障真实机器人应用强化学习时,其末端执行器的接触力比较柔顺,同时在机械臂身遇到意外的接触与碰撞时能及时推断出来并进行柔顺处理。